开始之前
- 拥有 API 密钥的 Olostep 账户: 免费获取,无需信用卡。你的前 500 个积分已包含在内。
- Zapier 账户: 任何计划都可以。免费计划可以手动运行 Zaps;付费计划支持定时和多步骤 Zaps。
- 无需编写代码: 本指南中的所有操作都通过 Zapier 的可视化编辑器完成。
设置
1
在 Zapier 中找到 Olostep
打开任何 Zap,点击 + 添加操作,然后搜索 Olostep。从结果中选择 Olostep。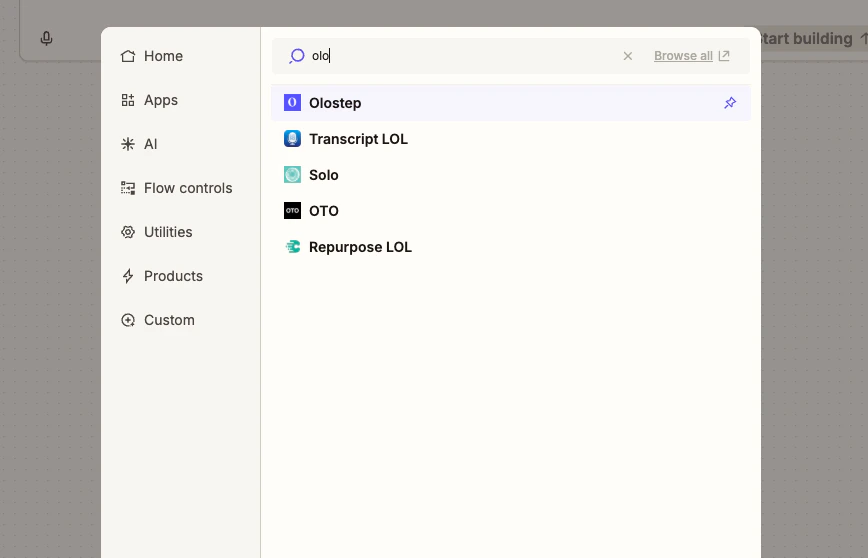
2
连接你的账户
点击 登录到 Olostep。将你的 API 密钥粘贴到字段中,然后点击 是,继续到 Olostep。Zapier 将验证密钥并保存凭据以供将来所有 Zaps 使用。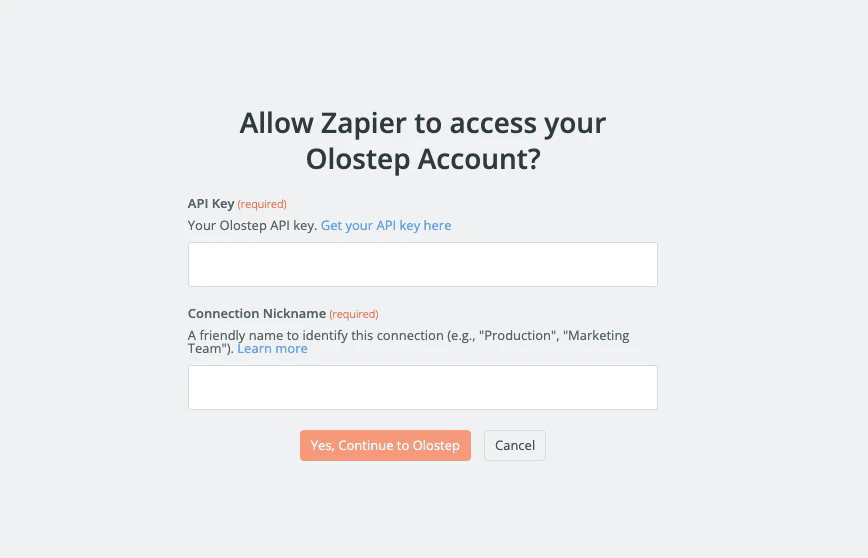
3
选择一个操作
连接账户后,从 Action 下拉菜单中选择五个 Olostep 操作之一,并填写所需字段。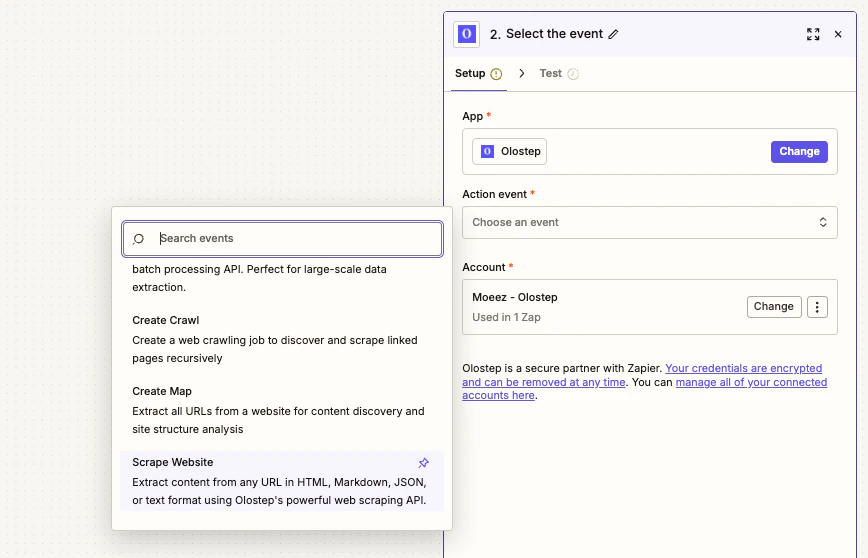
4
配置抓取网站(URL + 格式)
- 要抓取的 URL: 从你的触发器映射或手动输入
-
输出格式: 选择
Markdown、HTML、JSON或Text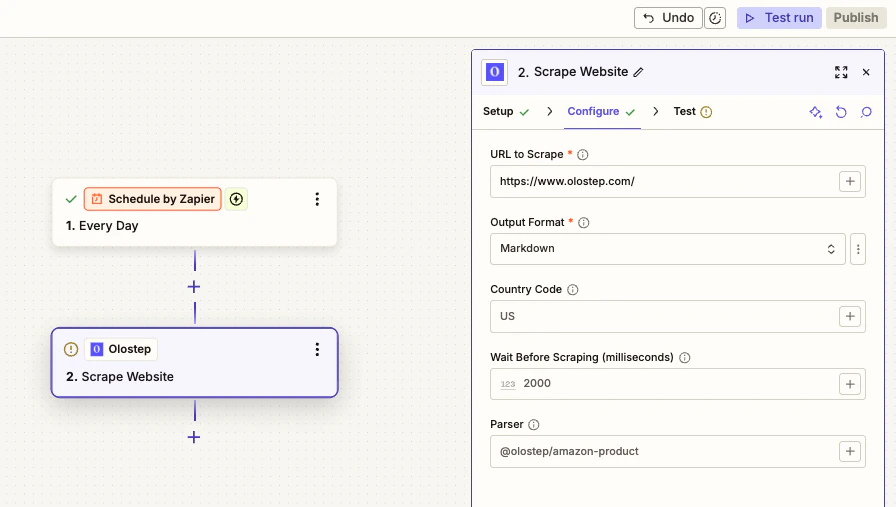
5
测试和发布
点击 测试步骤 运行实时请求并确认输出。一旦看起来正确,连接下游步骤并发布你的 Zap。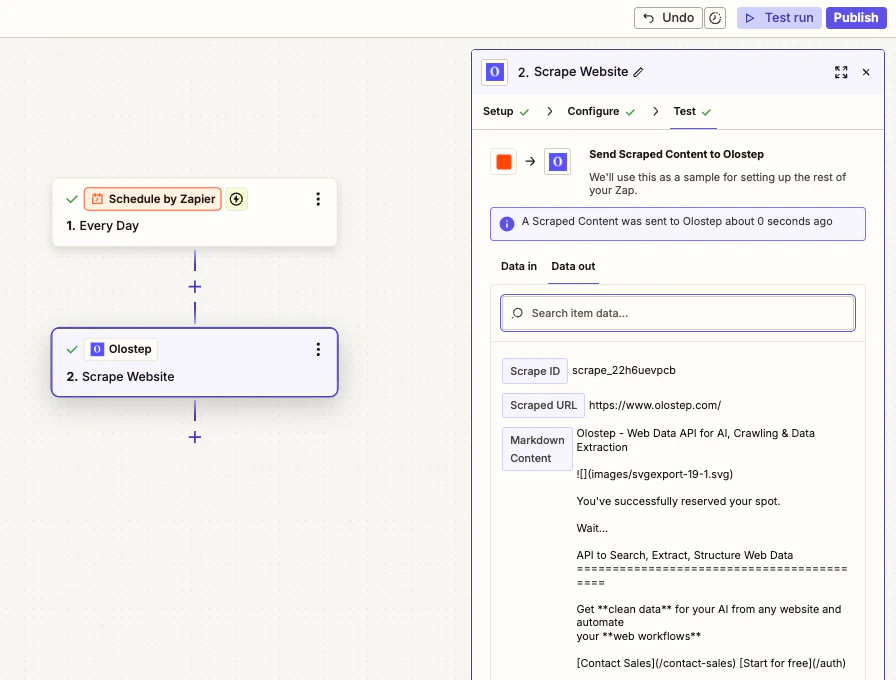
操作
抓取网站
将任何 URL 的内容提取为 Markdown、HTML、JSON 或纯文本。处理带有可选等待时间和国家定位的 JS 渲染页面。
询问 AI 答案
提出自然语言问题,并获取基于你提供的页面或实时网络搜索的引用答案。
批量抓取 URL
在一个作业中提交多达 100,000 个 URL,并行处理。返回一个
batch_id;异步检索结果。创建爬取
从一个 URL 开始,跟随链接并抓取所有子页面。适用于文档网站、博客或整个网站的摄取。返回一个
crawl_id。创建地图
获取网站上的每个 URL 而不抓取内容。在批处理作业之前用于发现。返回一个
map_id。批量、爬取和地图是异步的。 存储返回的 ID,并使用延迟步骤或第二个 Zap 在处理完成后检索结果。
示例工作流:每日竞争对手简报
它的功能: 每天早上,这个 Zap 抓取竞争对手页面,询问 Olostep AI 答案以总结该页面的关键更新,并将最终简报与引用一起发布到 Slack。 使用的节点: 由 Zapier 调度 -> Olostep 抓取网站 -> Olostep 询问 AI 答案 -> Slack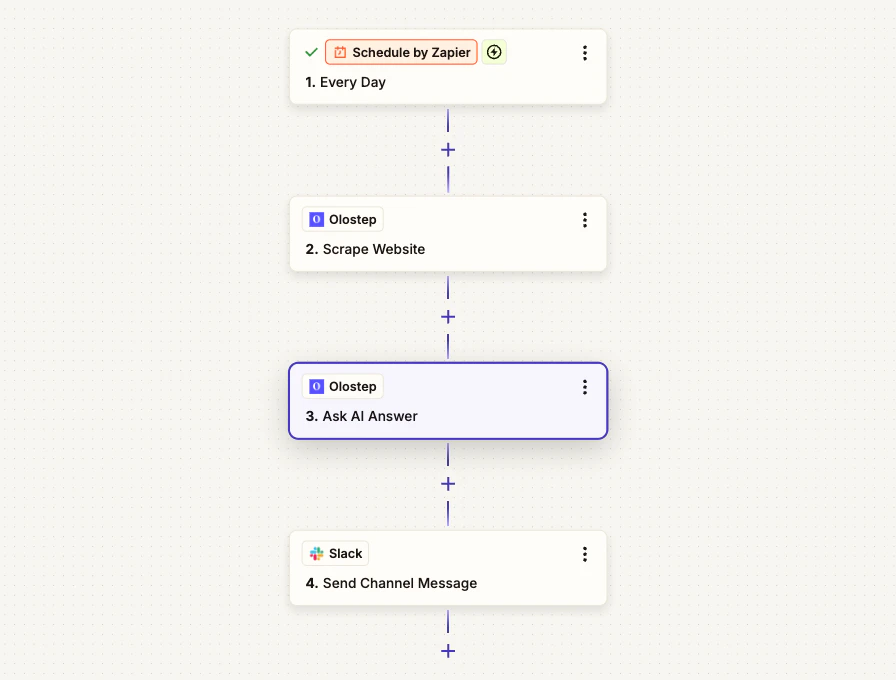
步骤 1:添加调度触发器
在 Zapier 中,创建一个新的 Zap 并将触发器设置为 由 Zapier 调度。设置为每天在适合你团队的时间运行(例如上午 8 点)。步骤 2:添加 Olostep 抓取网站
添加一个 Olostep 操作并选择 抓取网站。设置:- URL:
https://competitor.com/blog - 输出格式: Markdown
步骤 3:添加 Olostep 询问 AI 答案
添加第二个 Olostep 操作并选择 询问 AI 答案。设置:- 问题:
今天这个页面上的关键更新、公告、产品更改或价格更改是什么?返回一个简洁的简报,带有要点并包括引用。 - 上下文 URL(JSON 数组): 映射步骤 2 中的 抓取的 URL
- 格式: Markdown
- 包括引用: true
步骤 4:发送到 Slack
添加一个 Slack 操作,设置为 发送频道消息。映射:- 频道:
#competitive-intel - 消息文本:
每日竞争对手简报 - 消息正文:
{{Answer (Markdown)}}
你得到的
每天早上,你的 Slack 频道会收到一条消息,例如:每日竞争对手简报从这里你可以扩展这个 Zap:添加一个过滤器以仅在出现特定关键词时发布,将简报写入 Google Sheets 进行跟踪,或为不同的竞争对手 URL 运行单独的 Zaps。来源:competitor.com/blog, competitor.com/pricing
- 推出新的电子商务工作流程集成
- 更新定价页面,新增中档计划
- 发布两篇关于自动化最佳实践的新博客文章
解析器
在任何抓取或批处理操作的 Parser 字段中添加解析器 ID,以获取结构化数据而不是原始内容:
在 Olostep 解析器商店查看完整列表 →
Zapier 限制和解决方法
任务限制
Zapier 将每个操作计为一个任务,计入你计划的限制。 解决方法: 使用 批量抓取 URL 以单个任务处理多个 URL,而不是循环单个抓取操作。执行超时
Zaps 在 30 秒后超时。爬取和大型批处理作业需要更长时间。 解决方法: 存储返回的crawl_id 或 batch_id,并在由 webhook 触发或计划延迟的单独 Zap 中检索结果。
数据大小限制
Zapier 限制步骤之间可以传递的数据大小,这可能是大抓取负载的问题。 解决方法: 使用 Olostep 返回的托管输出 URL 单独获取大内容,而不是在步骤之间传递原始内容。轮询触发器
大多数 Zapier 触发器以 5-15 分钟的间隔轮询,而不是即时。 解决方法: 使用 Zapier 的 Webhooks 触发器进行即时通知,或在固定时间安排 Zaps,而不是依赖于近实时轮询。故障排除
API 密钥被拒绝
API 密钥被拒绝
直接从 olostep.com/dashboard 复制密钥,确保没有尾随空格。如果错误仍然存在,请断开并重新连接 Zapier 中的 Olostep 账户。
抓取的内容为空
抓取的内容为空
增加 抓取前等待时间(对于 JS 密集型页面,尝试 2000-5000ms)。确认 URL 可以在无需登录的情况下公开访问。如果特定域名始终失败,请联系 info@olostep.com。
批量 URL 格式错误
批量 URL 格式错误
要抓取的 URL 字段需要一个 JSON 数组:如果需要,使用上游的 Code by Zapier 步骤从你的数据构建此数组。
达到速率限制
达到速率限制
在抓取操作之间添加 延迟 步骤,或切换到 批量抓取 URL 而不是循环单个抓取。检查 仪表板 中的当前使用情况。
Zap 在爬取或批处理中超时
Zap 在爬取或批处理中超时
这些操作是异步设计的。在操作后立即存储返回的 ID,然后使用第二个 Zap 或计划轮询稍后检索结果。
相关
抓取 API
抓取端点的完整参考
批处理 API
批处理作业的工作原理以及如何检索结果
爬取 API
爬取配置和结果检索
地图 API
URL 发现和过滤选项
Zapier 网站
Zapier 平台