开始之前
- 拥有带有 API 密钥的 Olostep 账户: 免费获取,无需信用卡。你的前 500 个积分已包含在内。
- n8n 正在运行: 可以是 n8n Cloud 或自托管实例。社区节点必须启用(在大多数设置中默认启用)。
- 无需编码: 本指南中的所有操作均通过 n8n 的可视化编辑器完成。
设置
1
搜索 Olostep 节点
打开任意工作流,点击 +,搜索 Olostep。从结果中选择 Olostep Web Scraper。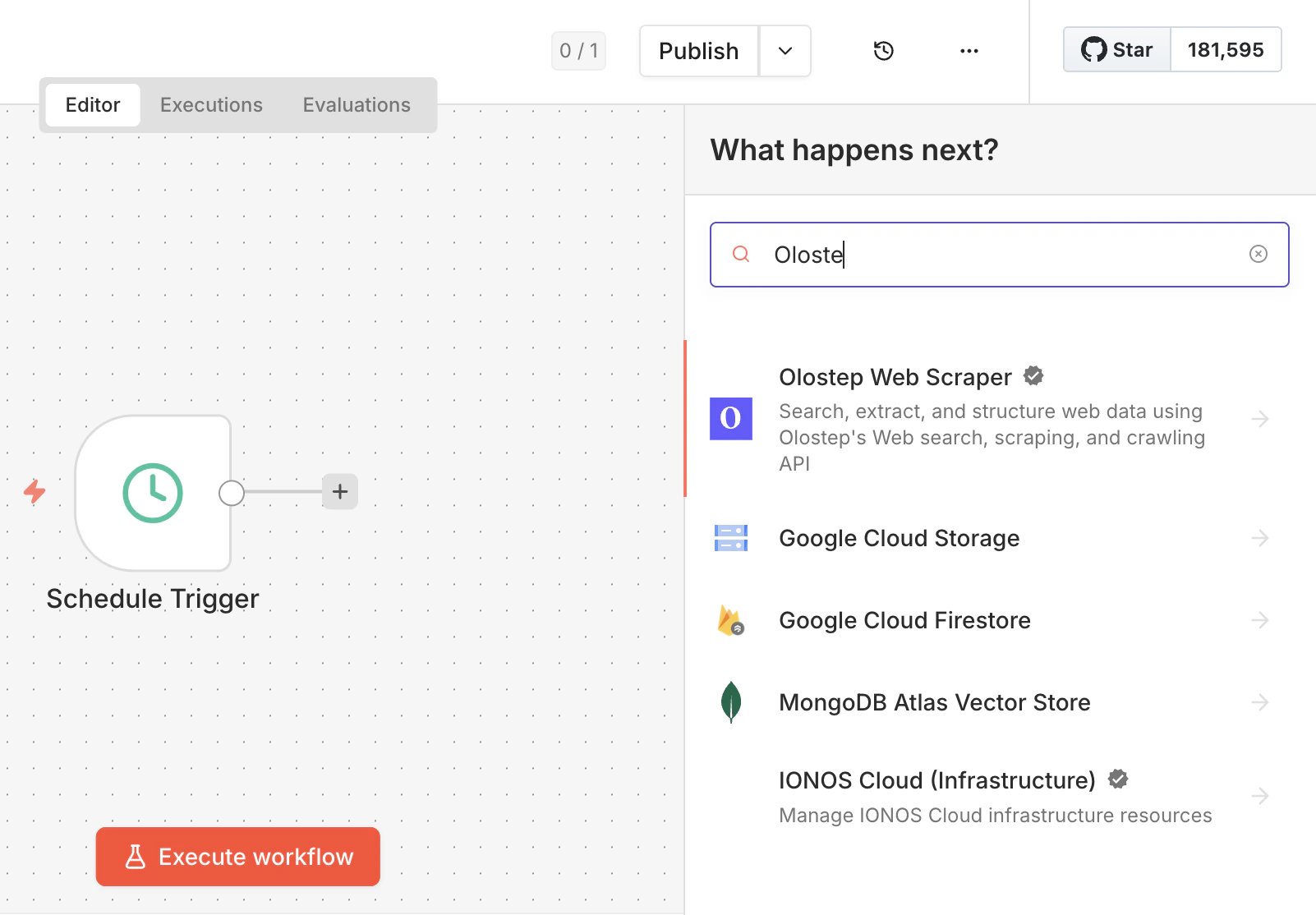
2
安装节点
点击结果以打开节点详情面板,然后点击 安装节点。n8n 将安装 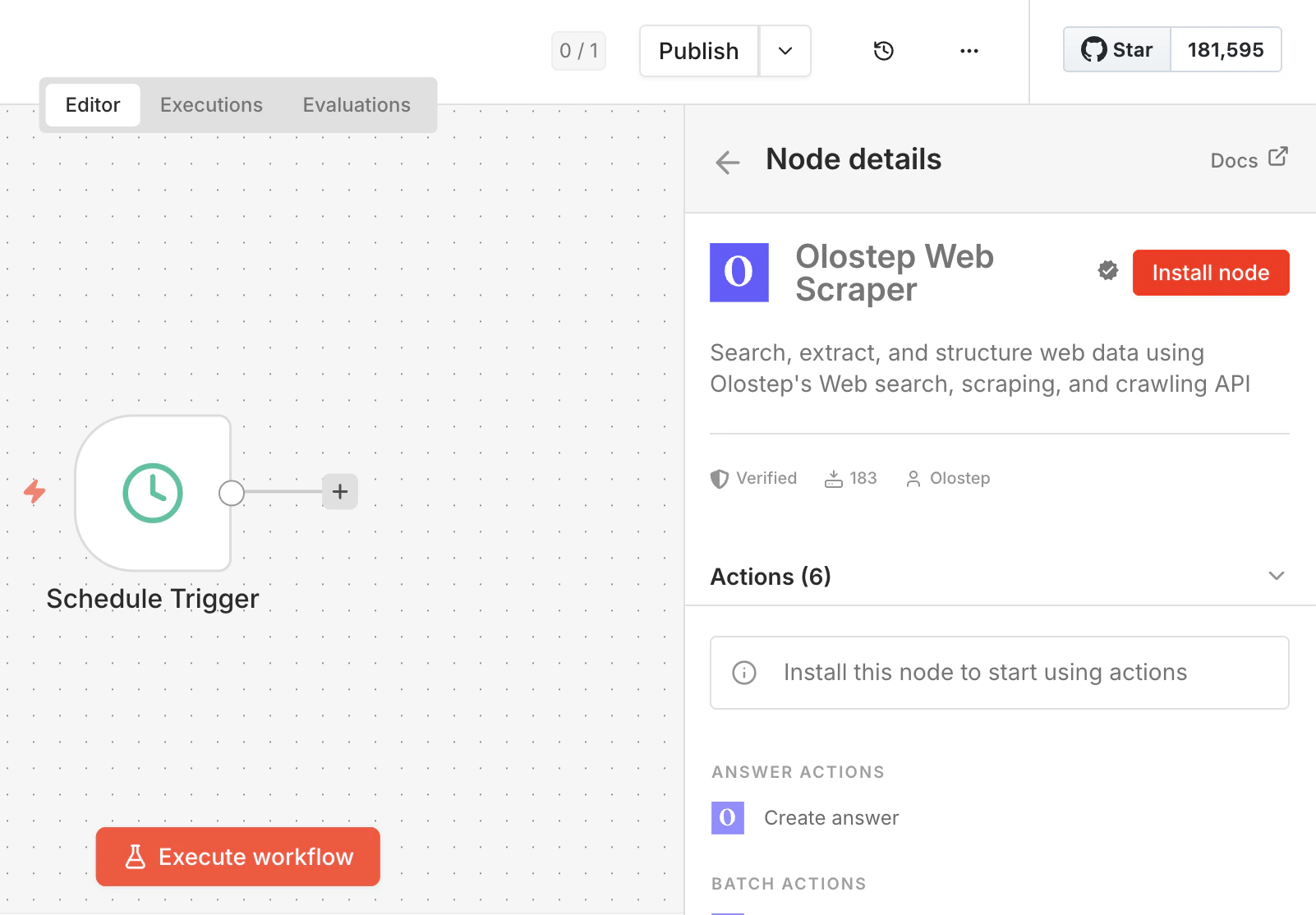
n8n-nodes-olostep 并提示你重启。请在继续之前执行此操作。如果你的工作空间禁用了 社区节点,管理员需要先启用它。请参阅 n8n 社区节点指南。
3
添加你的 API 密钥
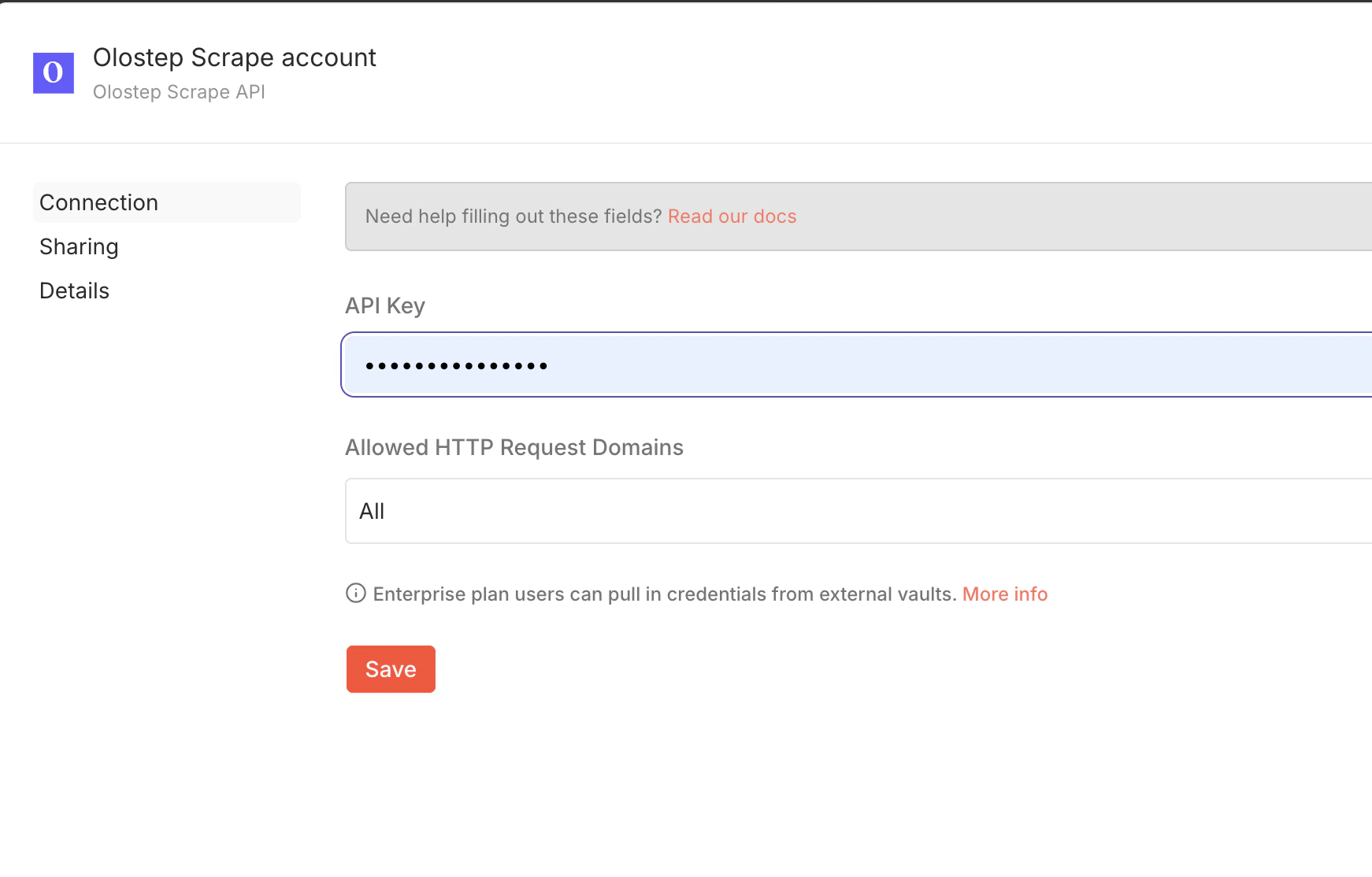
4
连接并运行
将 Olostep 节点连接到触发器和任何下游步骤,然后执行你的工作流。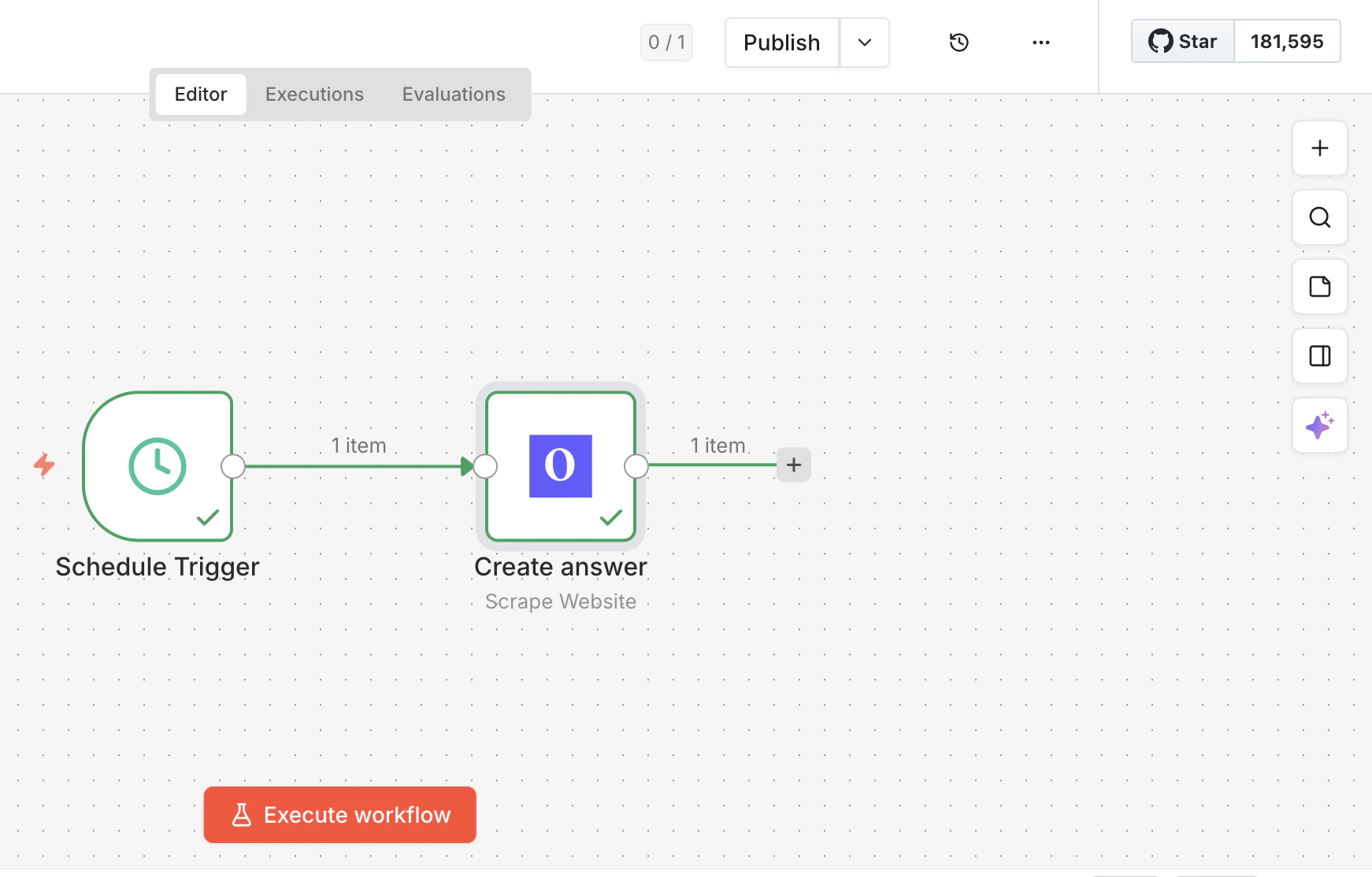
操作
抓取网站
从任何 URL 提取内容为 Markdown、HTML、JSON 或纯文本。处理 JS 渲染页面,支持可选等待时间和国家目标。
搜索
运行网页搜索并以 JSON 格式获取结构化结果(标题、URL 和摘要)。
答案(AI)
提出自然语言问题并获得带有引用来源的答案。在需要有依据的回答时,适合在 LLM 节点之前使用。
批量抓取 URL
在一个作业中提交最多 10,000 个 URL,并行处理。返回一个
batch_id;异步检索结果。创建爬取
从一个 URL 开始,跟随链接并抓取所有子页面。适用于文档网站、博客或全站点摄取。返回一个
crawl_id。创建地图
获取网站上的每个 URL 而不抓取内容。在批量作业之前用于发现。返回一个
map_id。批量、爬取和地图是异步的。 存储返回的 ID,并使用等待节点或第二个工作流在处理完成后检索结果。
示例工作流:从 Google Sheets 丰富潜在客户信息
它的作用: 当你将公司 URL 粘贴到 Google 表格中时,此工作流会自动抓取公司网站,使用 AI 节点提取关键信息,并将结果写回同一行,将空白电子表格变成填充的潜在客户数据库。 使用的节点: Google Sheets 触发器 → Olostep 抓取网站 → OpenAI → 代码 → Google Sheets 更新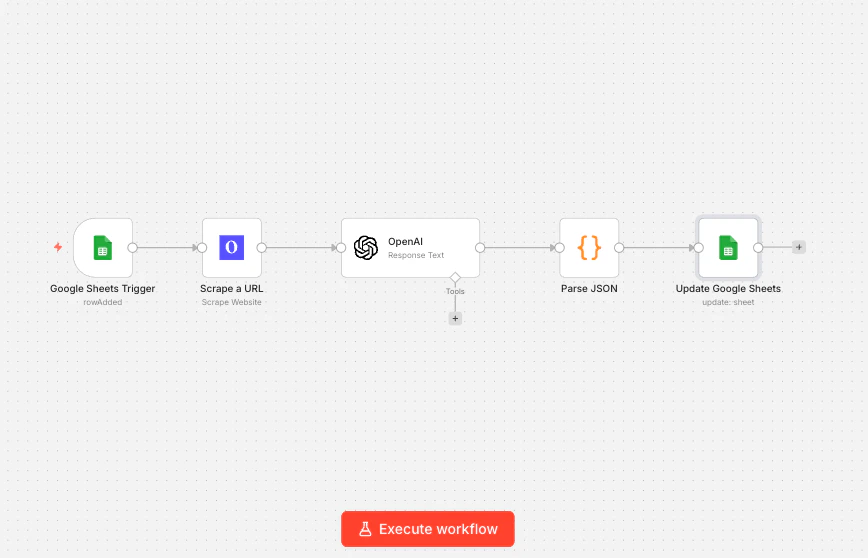
步骤 1:设置你的 Google 表格
创建一个包含以下列的表格:Company URL、Industry、Description、Company Size、Enriched。工作流从 Company URL 读取并填充其余部分。
步骤 2:添加 Google Sheets 触发器
在 n8n 中,添加一个 Google Sheets 触发器节点。将事件设置为 Row Added,指向你的表格,并设置为监视Company URL 列。现在每次你将新 URL 粘贴到表格中时,此工作流都会触发。
步骤 3:添加 Olostep 抓取网站
在触发器之后连接一个 Olostep Web Scraper 节点。设置:- Action: 抓取网站
- URL:
{{ $json["Company URL"] }}(从新行中提取 URL) - Output Format: Markdown
步骤 4:添加 OpenAI 节点
连接一个 OpenAI 节点。将模型设置为gpt-4o-mini(快速且适合提取任务),并使用以下提示:
markdownContent 字段是 Olostep 从抓取中返回的,作为干净的纯文本。
步骤 5:解析 AI 响应并写回
添加一个 代码 节点以解析来自 OpenAI 的 JSON:Industry→{{ $json.industry }}Description→{{ $json.description }}Company Size→{{ $json.company_size }}Enriched→Yes
你得到什么
将像https://notion.so 这样的 URL 粘贴到你的表格中,约 10 秒内该行会填充:
从这里你可以扩展此工作流:在丰富完成时添加 Slack 通知,在写回之前按行业过滤,或用 HubSpot 替换 Google Sheets 以直接更新联系人。
模板
准备导入的 n8n 工作流,使用 Olostep 构建:爬取文档 → AI 知识库
使用 Olostep 爬取文档网站,并将输出结构化为 AI 准备好的知识库。
Google Maps 潜在客户 → 决策者丰富
从 Google Maps 抓取商业潜在客户,并用决策者详细信息丰富它们。
挖掘用户投诉 → 洞察报告
使用 Olostep + Gemini 分析投诉,并在 Google Docs 中生成结构化的洞察报告。
Amazon 产品提取 → Google Sheets
使用 Olostep 提取 Amazon 产品 URL 和元数据,然后将结果同步到 Sheets。
解析器
在任何抓取或批量操作的 Parser 字段中添加解析器 ID,以获取结构化数据而不是原始内容:
在 Olostep 解析器商店 → 查看完整列表
故障排除
API 密钥被拒绝
API 密钥被拒绝
直接从 olostep.com/dashboard 复制密钥,确保没有尾随空格。如果错误仍然存在,请在 n8n 中删除并重新创建凭证。
抓取的内容为空
抓取的内容为空
增加 抓取前等待(对于 JS 密集页面,尝试 2000–5000ms)。确认 URL 可以在不登录的情况下公开访问。如果某个特定域名持续失败,请联系 info@olostep.com。
批量 URL 格式错误
批量 URL 格式错误
要抓取的 URL 字段需要一个 JSON 数组:如果需要,可以在上游使用代码节点从你的数据构建此数组。
达到速率限制
达到速率限制
在抓取步骤之间添加一个 等待 节点,或者改用 批量抓取 URL 而不是循环单个抓取。在 仪表板 中查看当前使用情况。
设置中看不到社区节点
设置中看不到社区节点
在 n8n Cloud 上,社区节点必须由工作空间所有者启用。在自托管中,确保环境中设置了
N8N_COMMUNITY_PACKAGES_ENABLED=true。请参阅 n8n 的安装指南。相关
抓取 API
抓取端点的完整参考
批量 API
批量作业的工作原理及如何检索结果
爬取 API
爬取配置和结果检索
地图 API
URL 发现和过滤选项
开始使用
准备好自动化你的网页搜索、抓取和爬取工作流了吗?n8n 网站
n8n 平台
安装节点
安装 n8n-nodes-olostep 并开始构建自动化工作流