Avant de commencer
- Un compte Olostep avec une clé API : obtenez-en une gratuitement, aucune carte de crédit requise. Vos 500 premiers crédits sont inclus.
- n8n en cours d’exécution : soit n8n Cloud soit une instance auto-hébergée. Les nœuds communautaires doivent être activés (ils le sont par défaut sur la plupart des configurations).
- Aucune programmation requise : tout dans ce guide est fait via l’éditeur visuel de n8n.
Configuration
1
Recherchez le nœud Olostep
Ouvrez n’importe quel workflow, cliquez sur +, et recherchez Olostep. Sélectionnez Olostep Web Scraper dans les résultats.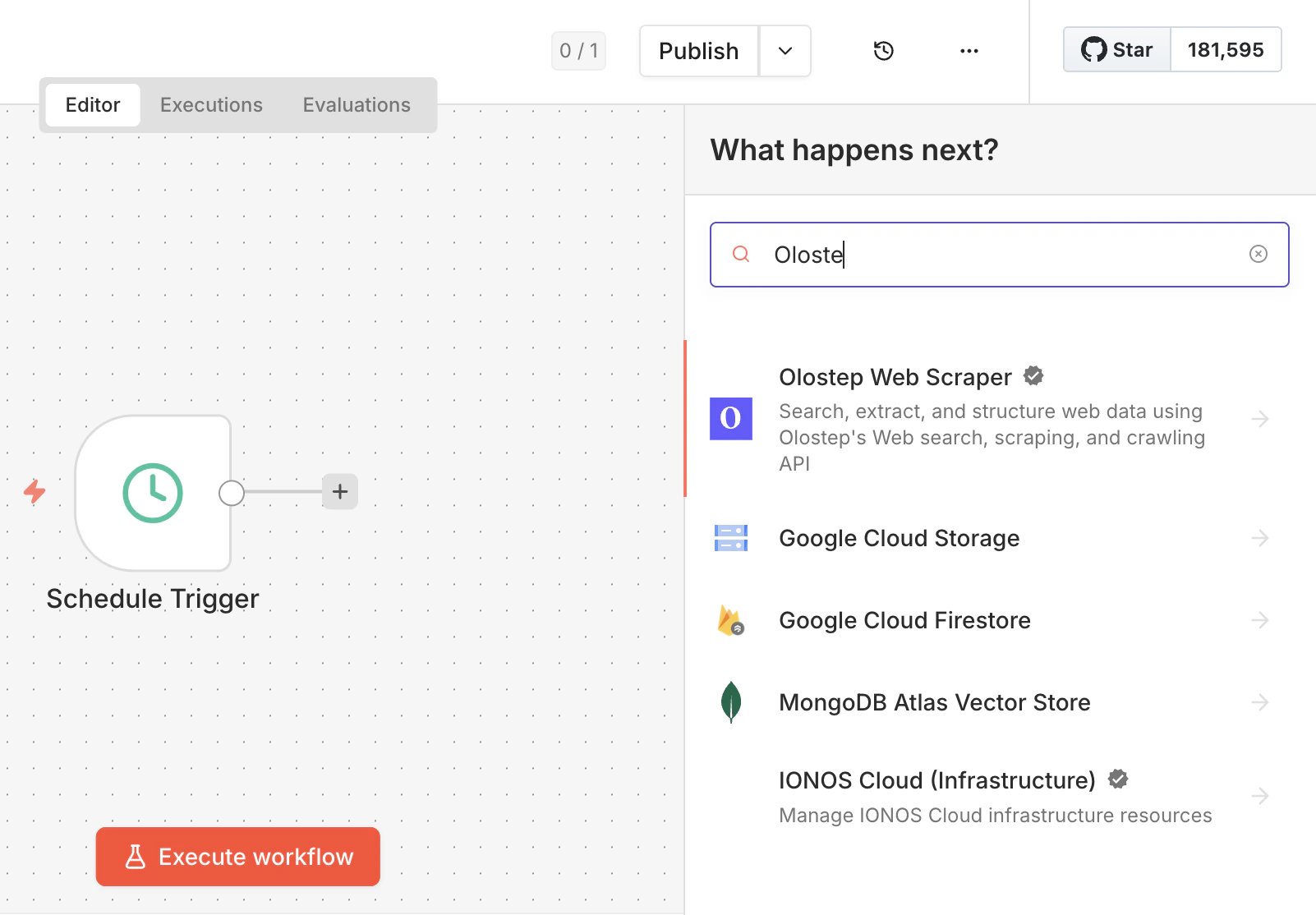
2
Installez le nœud
Cliquez sur le résultat pour ouvrir le panneau de détails du nœud, puis cliquez sur Installer le nœud. n8n installera 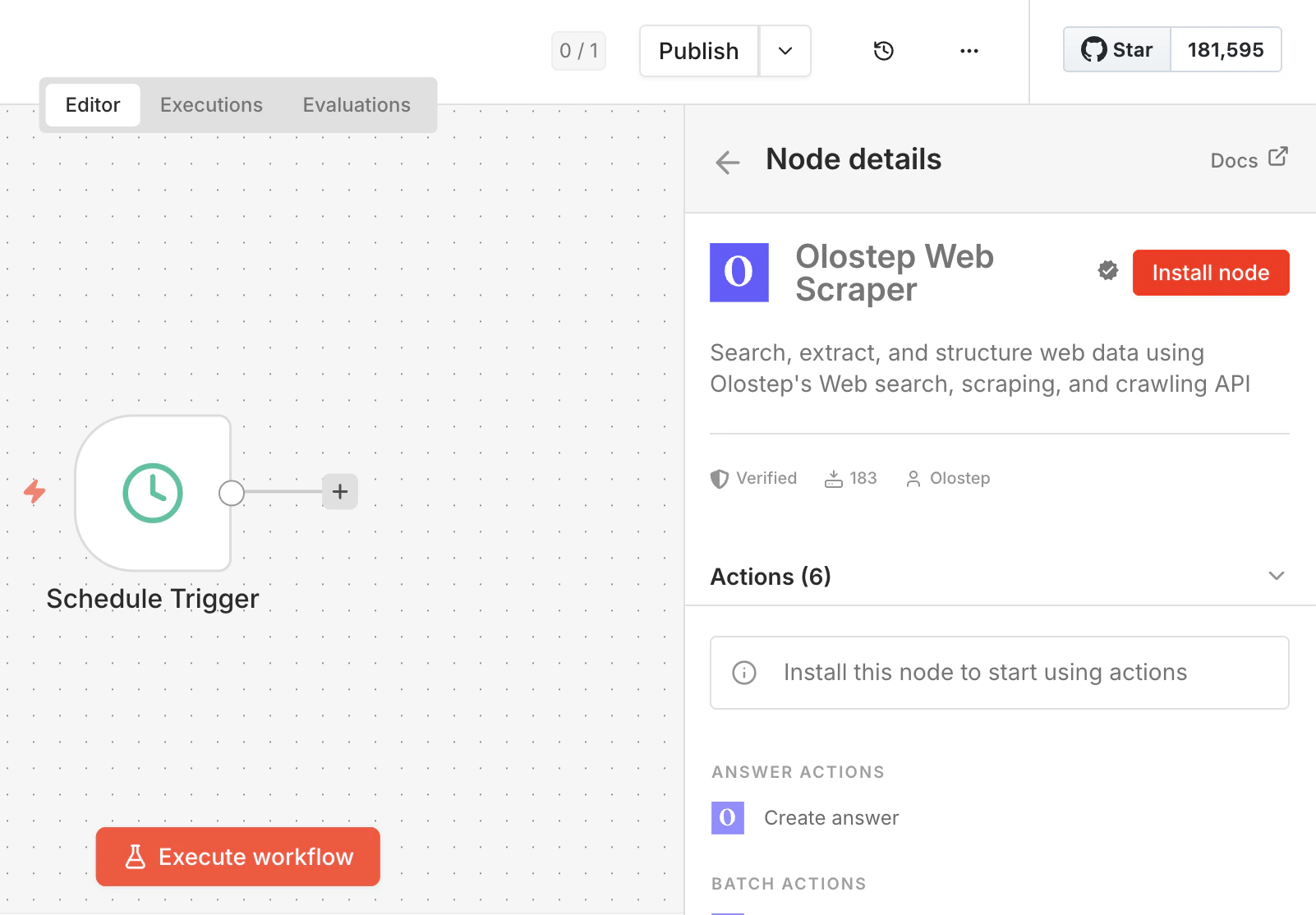
n8n-nodes-olostep et vous demandera de redémarrer. Faites-le avant de continuer.Si Nœuds Communautaires est désactivé pour votre espace de travail, un administrateur doit l’activer d’abord. Consultez le guide des nœuds communautaires n8n.
3
Ajoutez votre clé API
Ouvrez le nœud Olostep dans votre workflow, cliquez sur Configurer l’identification (dans l’onglet Paramètres), ajoutez votre clé API, et cliquez sur Enregistrer.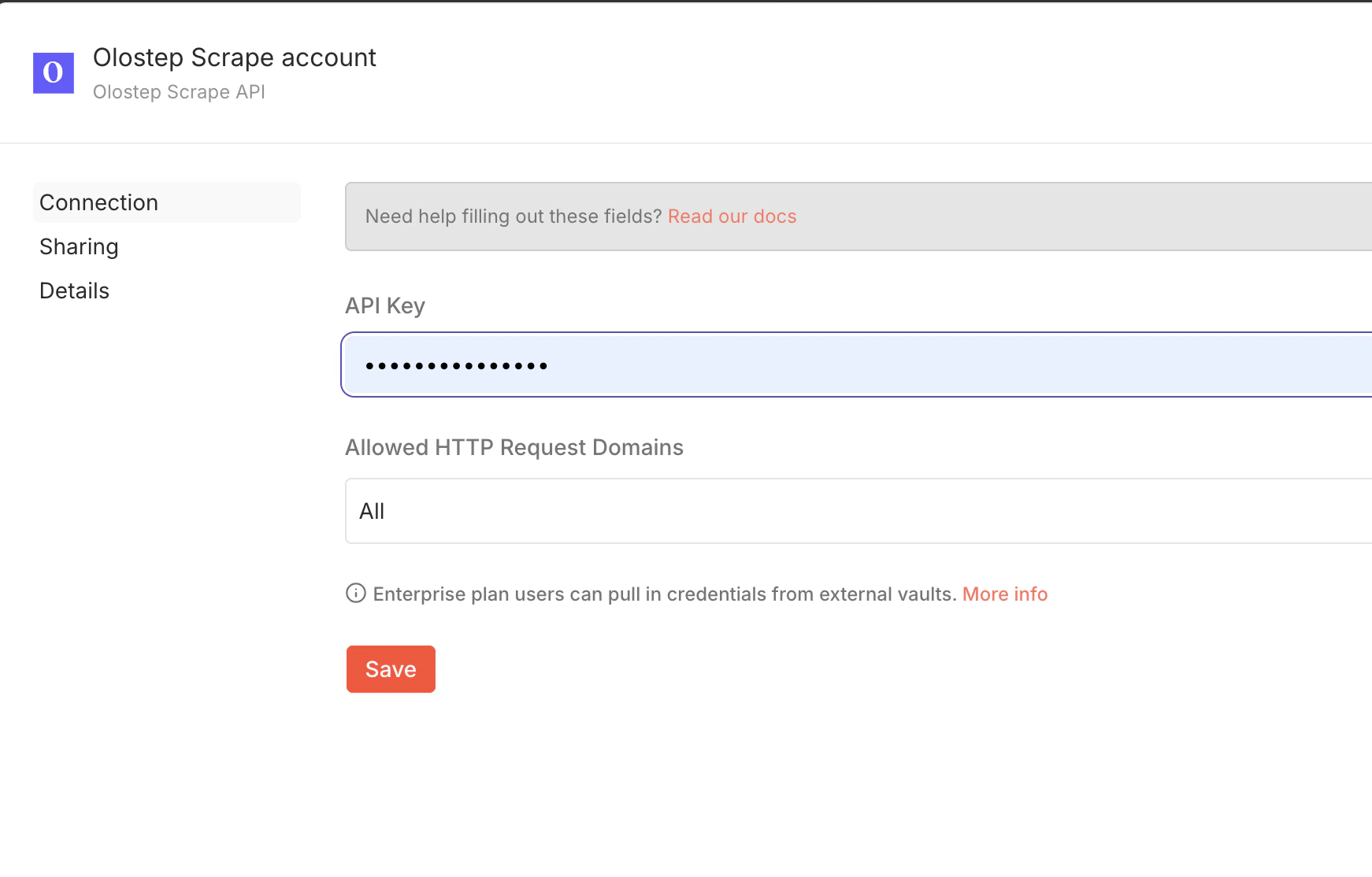
4
Connectez-le et exécutez
Connectez le nœud Olostep à un déclencheur et à toutes les étapes en aval, puis exécutez votre workflow.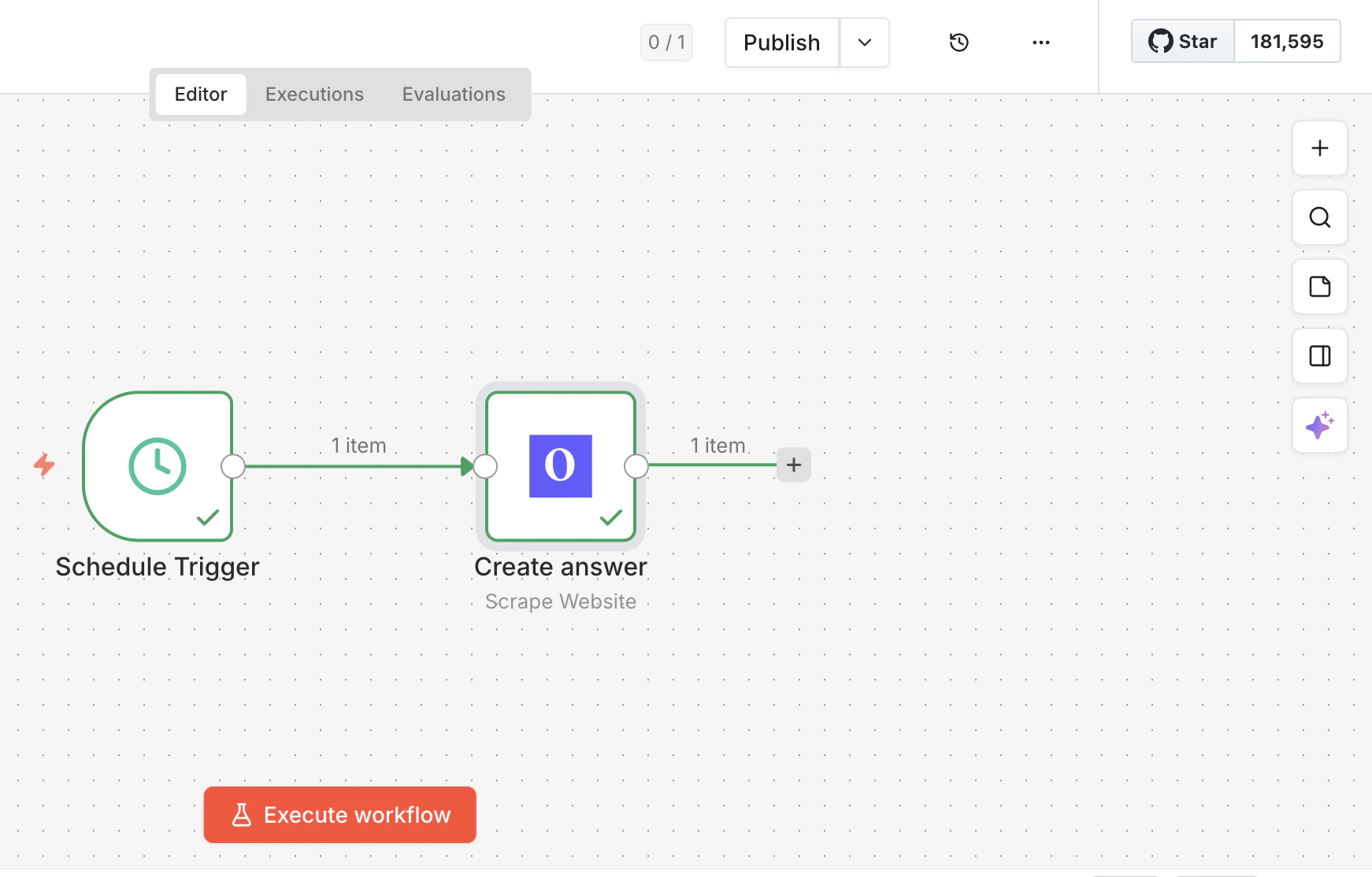
Actions
Scraper un site web
Extraire le contenu de n’importe quelle URL en tant que Markdown, HTML, JSON ou texte brut. Gère les pages rendues en JS avec des temps d’attente optionnels et un ciblage par pays.
Recherche
Effectuez une recherche sur le web et obtenez des résultats structurés (titres, URLs et extraits) en JSON.
Réponses (IA)
Posez une question en langage naturel et obtenez une réponse avec des sources citées. Utile avant les nœuds LLM lorsque vous avez besoin de réponses fondées.
Scraper des URLs par lots
Soumettez jusqu’à 10 000 URLs en un seul travail, traitées en parallèle. Retourne un
batch_id; récupérez les résultats de manière asynchrone.Créer un Crawl
Commencez à partir d’une URL, suivez les liens et scrapez toutes les sous-pages. Idéal pour les sites de documentation, les blogs ou l’ingestion complète de sites. Retourne un
crawl_id.Créer une Carte
Obtenez chaque URL sur un site sans scraper le contenu. Utilisez-le pour la découverte avant un travail par lots. Retourne un
map_id.Batch, Crawl, et Map sont asynchrones. Stockez l’ID retourné et utilisez un nœud d’attente ou un second workflow pour récupérer les résultats une fois le traitement terminé.
Exemple de workflow : Enrichissement de leads depuis Google Sheets
Ce qu’il fait : Lorsque vous collez une URL d’entreprise dans une feuille Google, ce workflow scrape automatiquement le site web de l’entreprise, extrait des informations clés avec un nœud IA, et écrit les résultats dans la même ligne, transformant une feuille de calcul vide en une base de données de leads remplie. Nœuds utilisés : Déclencheur Google Sheets → Olostep Scrape Website → OpenAI → Code → Mise à jour Google Sheets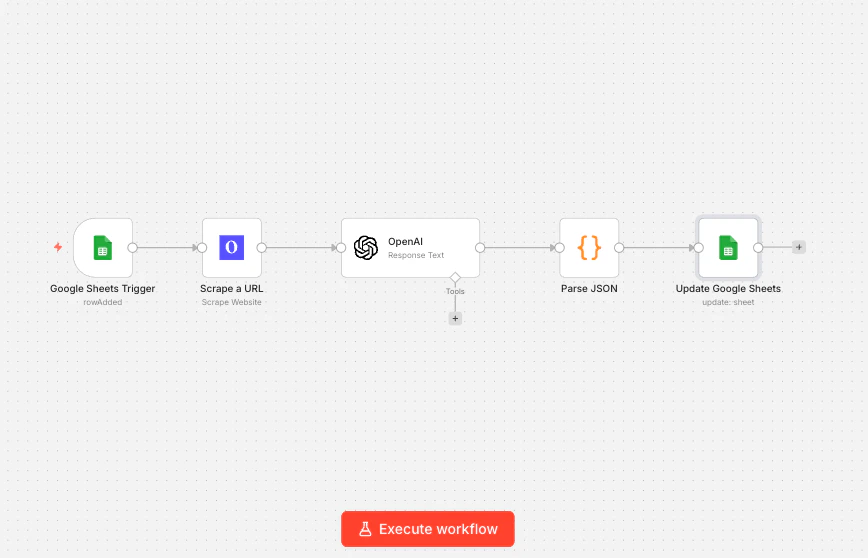
Étape 1 : Configurez votre feuille Google
Créez une feuille avec ces colonnes :Company URL, Industry, Description, Company Size, Enriched. Le workflow lit à partir de Company URL et remplit le reste.
Étape 2 : Ajoutez un déclencheur Google Sheets
Dans n8n, ajoutez un nœud de déclencheur Google Sheets. Définissez l’événement sur Row Added, pointez-le vers votre feuille, et configurez-le pour surveiller la colonneCompany URL. Maintenant, chaque fois que vous collez une nouvelle URL dans la feuille, ce workflow se déclenche.
Étape 3 : Ajoutez Olostep Scrape Website
Connectez un nœud Olostep Web Scraper après le déclencheur. Configurez :- Action : Scraper un site web
- URL :
{{ $json["Company URL"] }}(extrait l’URL de la nouvelle ligne) - Format de sortie : Markdown
Étape 4 : Ajoutez un nœud OpenAI
Connectez un nœud OpenAI. Définissez le modèle surgpt-4o-mini (rapide et économique pour les tâches d’extraction) et utilisez ce prompt :
markdownContent est ce que Olostep renvoie du scrape, sous forme de texte clair.
Étape 5 : Analysez la réponse IA et écrivez en retour
Ajoutez un nœud Code pour analyser le JSON d’OpenAI :Industry→{{ $json.industry }}Description→{{ $json.description }}Company Size→{{ $json.company_size }}Enriched→Yes
Ce que vous obtenez
Collez une URL commehttps://notion.so dans votre feuille, et en ~10 secondes la ligne se remplit :
À partir de là, vous pouvez étendre ce workflow : ajoutez une notification Slack lorsque l’enrichissement est terminé, filtrez par industrie avant d’écrire en retour, ou remplacez Google Sheets par HubSpot pour mettre à jour directement les contacts.
Modèles
Workflows n8n prêts à importer construits avec Olostep :Crawl docs → base de connaissances IA
Crawl des sites de documentation avec Olostep et structurez la sortie en une base de connaissances prête pour l’IA.
Leads Google Maps → enrichissement décideur
Scrapez des leads d’affaires depuis Google Maps et enrichissez-les avec des détails sur les décideurs.
Exploiter les plaintes utilisateurs → rapport d'insights
Analysez les plaintes avec Olostep + Gemini et générez des rapports d’insights structurés dans Google Docs.
Extraction de produits Amazon → Google Sheets
Extrayez les URLs et métadonnées de produits Amazon avec Olostep, puis synchronisez les résultats avec Sheets.
Parseurs
Ajoutez un ID de parseur au champ Parser sur toute action de Scrape ou Batch pour obtenir des données structurées au lieu de contenu brut :
Voir la liste complète dans le magasin de parseurs Olostep →
Dépannage
Clé API rejetée
Clé API rejetée
Copiez la clé directement depuis olostep.com/dashboard sans espaces de fin. Supprimez et recréez l’identification dans n8n si l’erreur persiste.
Contenu scrappé vide
Contenu scrappé vide
Augmentez Attendre avant de scraper (essayez 2000–5000ms pour les pages lourdes en JS). Assurez-vous que l’URL est accessible publiquement sans connexion. Si un domaine spécifique échoue constamment, contactez info@olostep.com.
Erreur de format d'URL par lot
Erreur de format d'URL par lot
Le champ URLs à scraper attend un tableau JSON :Utilisez un nœud Code en amont pour construire ce tableau à partir de vos données si nécessaire.
Limite de taux atteinte
Limite de taux atteinte
Ajoutez un nœud Attendre entre les étapes de scrape, ou passez à Scraper des URLs par lots au lieu de boucler des scrapes uniques. Vérifiez l’utilisation actuelle dans le tableau de bord.
Nœuds communautaires non visibles dans les paramètres
Nœuds communautaires non visibles dans les paramètres
Sur n8n Cloud, les nœuds communautaires doivent être activés par un propriétaire d’espace de travail. Sur auto-hébergé, assurez-vous que
N8N_COMMUNITY_PACKAGES_ENABLED=true est défini dans votre environnement. Voir le guide d’installation de n8n.Connexes
API Scrapes
Référence complète pour le point de terminaison de scrape
API Batches
Comment fonctionnent les tâches par lots et comment récupérer les résultats
API Crawls
Configuration de crawl et récupération des résultats
API Maps
Découverte d’URL et options de filtrage
Commencez
Prêt à automatiser vos workflows de recherche web, de scraping et de crawling ?Site Web n8n
Plateforme n8n
Installez le nœud
Installez n8n-nodes-olostep et commencez à créer des workflows automatisés