Avant de commencer
- Un compte Olostep avec une clé API : obtenez-en une gratuitement, aucune carte de crédit requise. Vos 500 premiers crédits sont inclus.
- Un compte Zapier : n’importe quel plan fonctionne. Les plans gratuits peuvent exécuter des Zaps manuellement ; les plans payants prennent en charge les Zaps programmés et multi-étapes.
- Aucune programmation requise : tout dans ce guide est réalisé via l’éditeur visuel de Zapier.
Configuration
1
Trouver Olostep dans Zapier
Ouvrez n’importe quel Zap, cliquez sur + pour ajouter une action, et recherchez Olostep. Sélectionnez Olostep dans les résultats.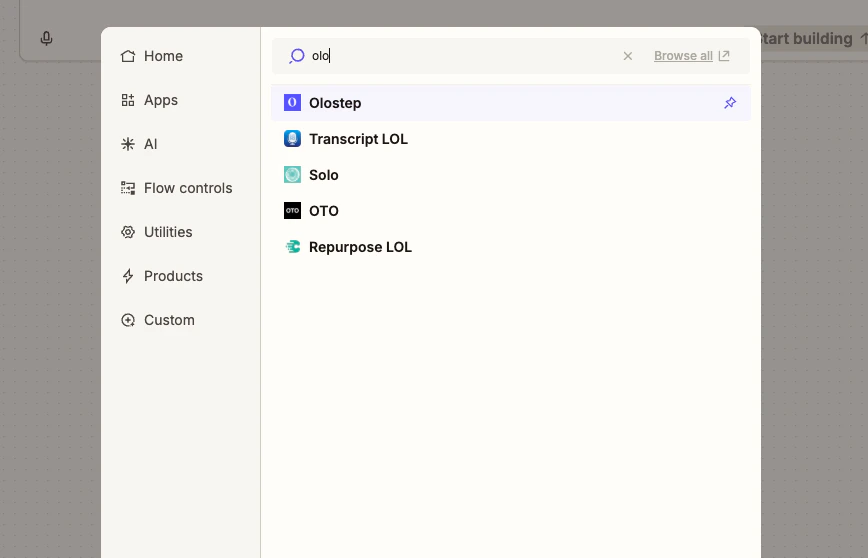
2
Connectez votre compte
Cliquez sur Se connecter à Olostep. Collez votre clé API dans le champ et cliquez sur Oui, continuer vers Olostep. Zapier vérifiera la clé et enregistrera les informations d’identification pour tous les futurs Zaps.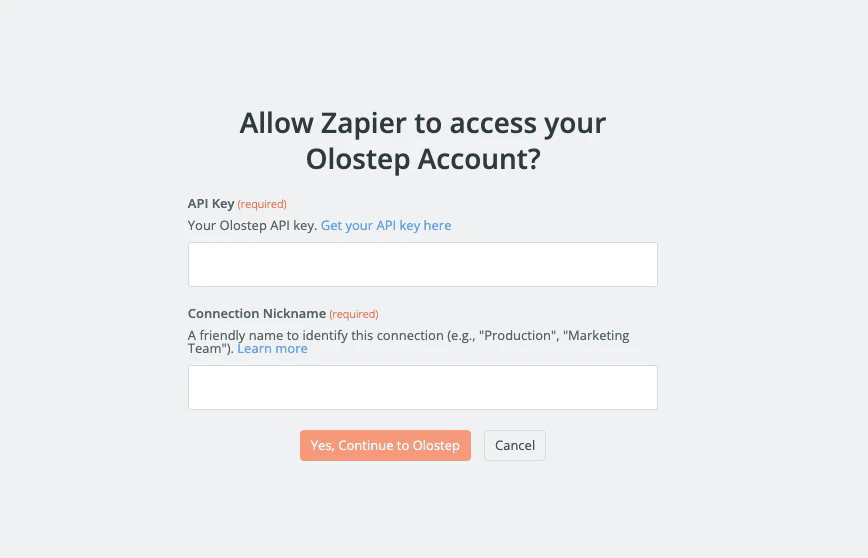
3
Choisissez une action
Avec votre compte connecté, choisissez l’une des cinq actions Olostep dans le menu déroulant Action et remplissez les champs requis.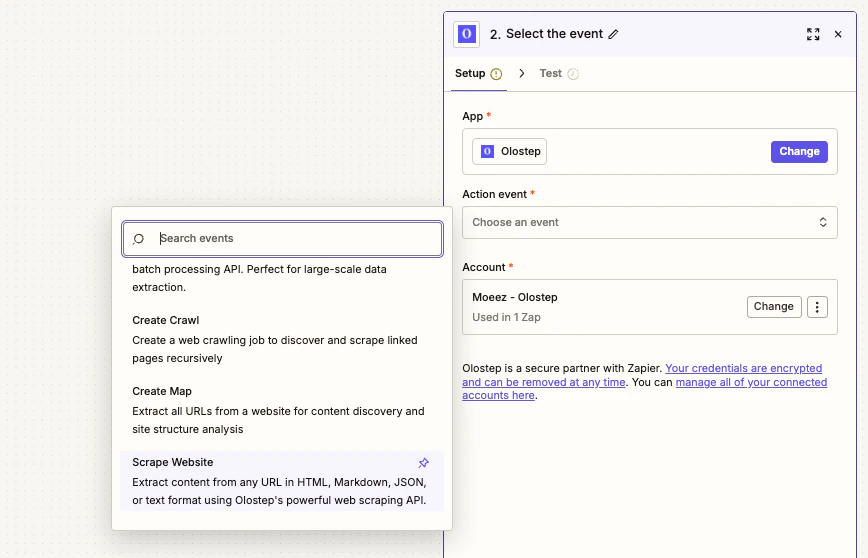
4
Configurer Scraper un site web (URL + format)
- URL à scraper : mappez-la depuis votre déclencheur ou entrez-la manuellement
-
Format de sortie : choisissez
Markdown,HTML,JSON, ouTexte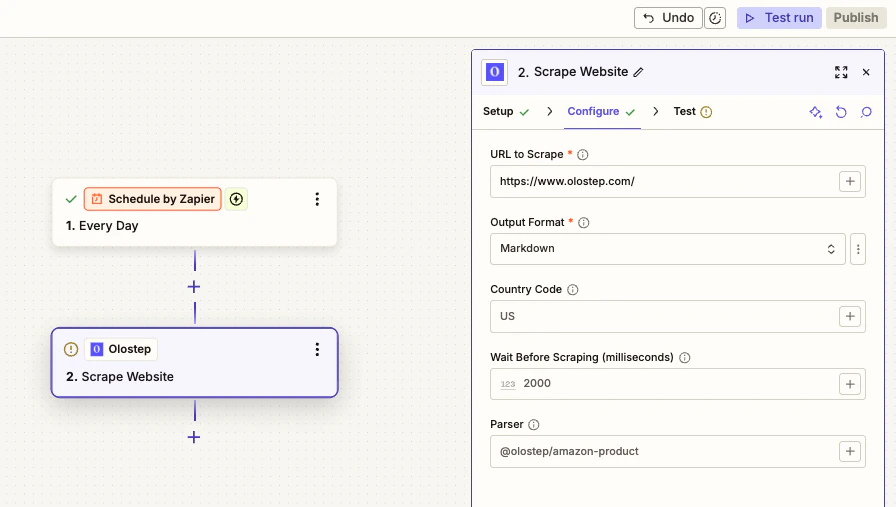
5
Tester et publier
Cliquez sur Tester l’étape pour exécuter une requête en direct et confirmer la sortie. Une fois que cela semble correct, connectez les étapes suivantes et publiez votre Zap.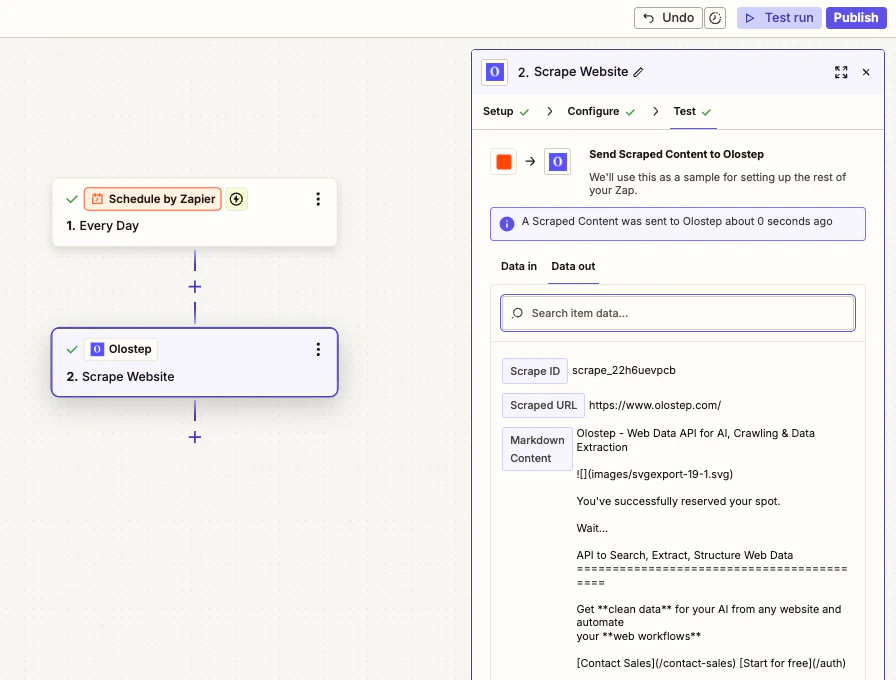
Actions
Scraper un site web
Extraire le contenu de n’importe quelle URL sous forme de Markdown, HTML, JSON ou texte brut. Gère les pages rendues en JS avec des temps d’attente optionnels et un ciblage par pays.
Demander une réponse IA
Posez une question en langage naturel et obtenez une réponse citée basée sur les pages que vous fournissez ou une recherche web en direct.
Scraper des URLs par lots
Soumettez jusqu’à 100 000 URLs en un seul travail, traitées en parallèle. Retourne un
batch_id; récupérez les résultats de manière asynchrone.Créer un crawl
Commencez à partir d’une URL, suivez les liens et scrapez toutes les sous-pages. Idéal pour les sites de documentation, les blogs ou l’ingestion complète de sites. Retourne un
crawl_id.Créer une carte
Obtenez chaque URL sur un site sans scraper le contenu. Utilisez-le pour la découverte avant un travail par lots. Retourne un
map_id.Batch, Crawl et Map sont asynchrones. Stockez l’ID retourné et utilisez une étape de délai ou un second Zap pour récupérer les résultats une fois le traitement terminé.
Exemple de flux de travail : Briefing quotidien sur les concurrents
Ce qu’il fait : Chaque matin, ce Zap scrape une page concurrente, demande à Olostep AI Answer de résumer les mises à jour clés de cette page, et publie le briefing final avec des citations sur Slack. Nœuds utilisés : Schedule by Zapier -> Olostep Scraper un site web -> Olostep Demander une réponse IA -> Slack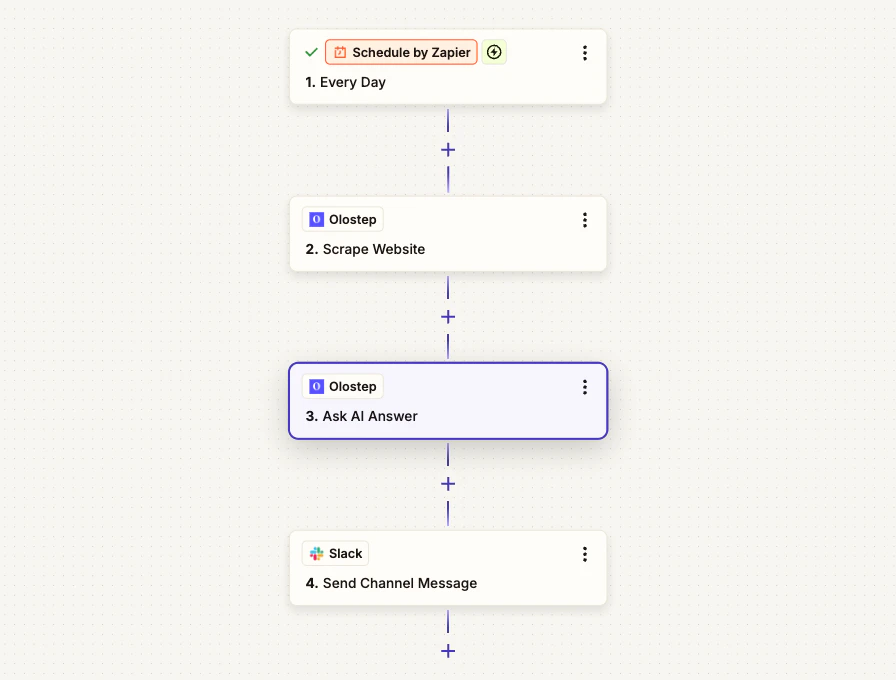
Étape 1 : Ajouter un déclencheur de planification
Dans Zapier, créez un nouveau Zap et définissez le déclencheur sur Schedule by Zapier. Réglez-le pour s’exécuter Chaque jour à une heure qui convient à votre équipe (par exemple, 8h).Étape 2 : Ajouter Olostep Scraper un site web
Ajoutez une action Olostep et choisissez Scraper un site web. Réglez :- URL :
https://competitor.com/blog - Format de sortie : Markdown
Étape 3 : Ajouter Olostep Demander une réponse IA
Ajoutez une deuxième action Olostep et choisissez Demander une réponse IA. Réglez :- Question :
Quelles sont les mises à jour clés, annonces, changements de produit ou changements de prix sur cette page aujourd'hui ? Retournez un briefing concis avec des points à puces et incluez des citations. - URLs de contexte (Tableau JSON) : mappez l’URL scrappée de l’étape 2
- Format : Markdown
- Inclure des citations : true
Étape 4 : Envoyer à Slack
Ajoutez une action Slack réglée sur Envoyer un message de canal. Mappez :- Canal :
#competitive-intel - Texte du message :
Briefing quotidien sur les concurrents - Corps du message :
{{Answer (Markdown)}}
Ce que vous obtenez
Chaque matin, votre canal Slack reçoit un message comme :Briefing quotidien sur les concurrentsÀ partir de là, vous pouvez étendre ce Zap : ajoutez un filtre pour ne publier que si des mots-clés spécifiques apparaissent, écrivez des briefings dans Google Sheets pour le suivi, ou exécutez des Zaps séparés pour différentes URLs de concurrents.Sources : competitor.com/blog, competitor.com/pricing
- Lancement d’une nouvelle intégration pour les workflows e-commerce
- Mise à jour de la page de tarification avec un nouveau plan intermédiaire
- Publication de deux nouveaux articles de blog sur les meilleures pratiques d’automatisation
Parseurs
Ajoutez un ID de parseur au champ Parseur sur n’importe quelle action de Scrape ou de Batch pour obtenir des données structurées au lieu de contenu brut :
Voir la liste complète dans le magasin de parseurs Olostep →
Limitations & Solutions de contournement de Zapier
Limites de tâches
Zapier compte chaque action comme une tâche contre la limite de votre plan. Solution de contournement : Utilisez Scraper des URLs par lots pour traiter plusieurs URLs comme une seule tâche au lieu de boucler une action de scrape unique.Délai d’exécution
Les Zaps expirent après 30 secondes. Les crawls et les grands travaux par lots prennent plus de temps. Solution de contournement : Stockez lecrawl_id ou batch_id retourné et récupérez les résultats dans un Zap séparé déclenché par un webhook ou un délai programmé.
Limites de taille des données
Zapier limite la taille des données pouvant passer entre les étapes, ce qui peut poser problème avec de grandes charges de scraping. Solution de contournement : Utilisez les URLs de sortie hébergées retournées par Olostep pour récupérer le contenu volumineux séparément plutôt que de passer le contenu brut entre les étapes.Déclencheurs de sondage
La plupart des déclencheurs Zapier sondent à un intervalle de 5 à 15 minutes, pas instantanément. Solution de contournement : Utilisez le déclencheur Webhooks de Zapier pour une notification instantanée, ou programmez les Zaps à des heures fixes plutôt que de compter sur un sondage quasi en temps réel.Dépannage
Clé API rejetée
Clé API rejetée
Copiez la clé directement depuis olostep.com/dashboard sans espaces de fin. Déconnectez et reconnectez le compte Olostep dans Zapier si l’erreur persiste.
Contenu scrappé vide
Contenu scrappé vide
Augmentez Attendre avant de scraper (essayez 2000–5000ms pour les pages lourdes en JS). Confirmez que l’URL est accessible publiquement sans connexion. Si un domaine spécifique échoue constamment, contactez info@olostep.com.
Erreur de format d'URL par lots
Erreur de format d'URL par lots
Le champ URLs à scraper attend un tableau JSON :Utilisez une étape Code by Zapier en amont pour construire ce tableau à partir de vos données si nécessaire.
Limite de taux atteinte
Limite de taux atteinte
Ajoutez une étape Délai entre les actions de scrape, ou passez à Scraper des URLs par lots au lieu de boucler des scrapes uniques. Vérifiez l’utilisation actuelle dans le tableau de bord.
Le Zap expire sur crawl ou batch
Le Zap expire sur crawl ou batch
Ces opérations sont conçues pour être asynchrones. Stockez l’ID retourné immédiatement après l’action, puis utilisez un deuxième Zap ou un sondage programmé pour récupérer les résultats plus tard.
Connexes
API de Scraping
Référence complète pour le point de terminaison de scraping
API de Batches
Comment fonctionnent les travaux par lots et comment récupérer les résultats
API de Crawls
Configuration de crawl et récupération des résultats
API de Maps
Découverte d’URL et options de filtrage
Site web de Zapier
Plateforme Zapier