Bevor du anfängst
- Ein Olostep-Konto mit einem API-Schlüssel: kostenlos erhalten, keine Kreditkarte erforderlich. Deine ersten 500 Credits sind inklusive.
- n8n läuft: entweder n8n Cloud oder eine selbstgehostete Instanz. Community Nodes müssen aktiviert sein (sie sind standardmäßig in den meisten Setups aktiviert).
- Kein Coding erforderlich: Alles in diesem Leitfaden wird über den visuellen Editor von n8n durchgeführt.
Einrichtung
1
Suche nach dem Olostep-Node
Öffne einen beliebigen Workflow, klicke auf + und suche nach Olostep. Wähle Olostep Web Scraper aus den Ergebnissen aus.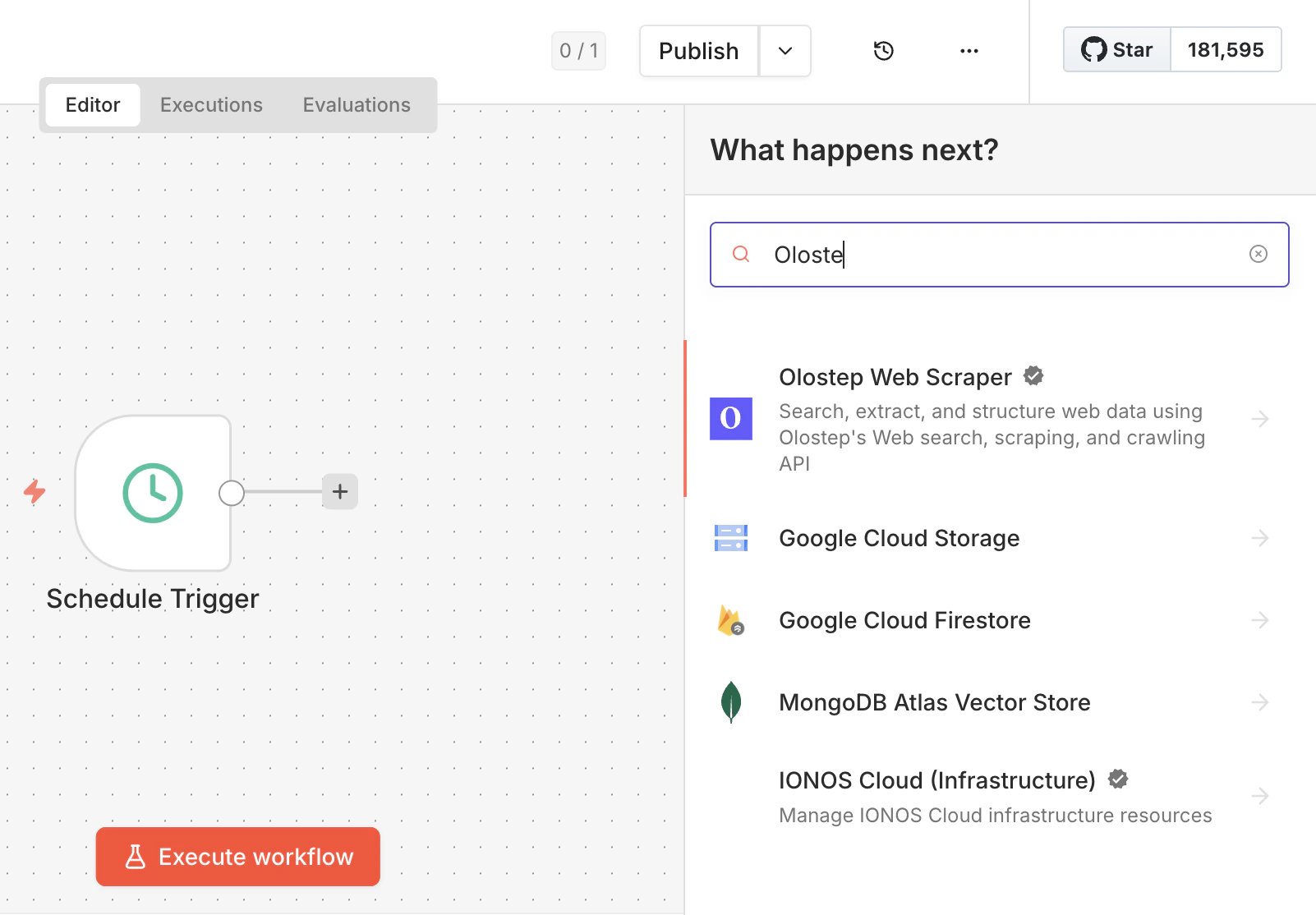
2
Installiere den Node
Klicke auf das Ergebnis, um das Node-Detailfenster zu öffnen, und klicke dann auf Node installieren. n8n wird 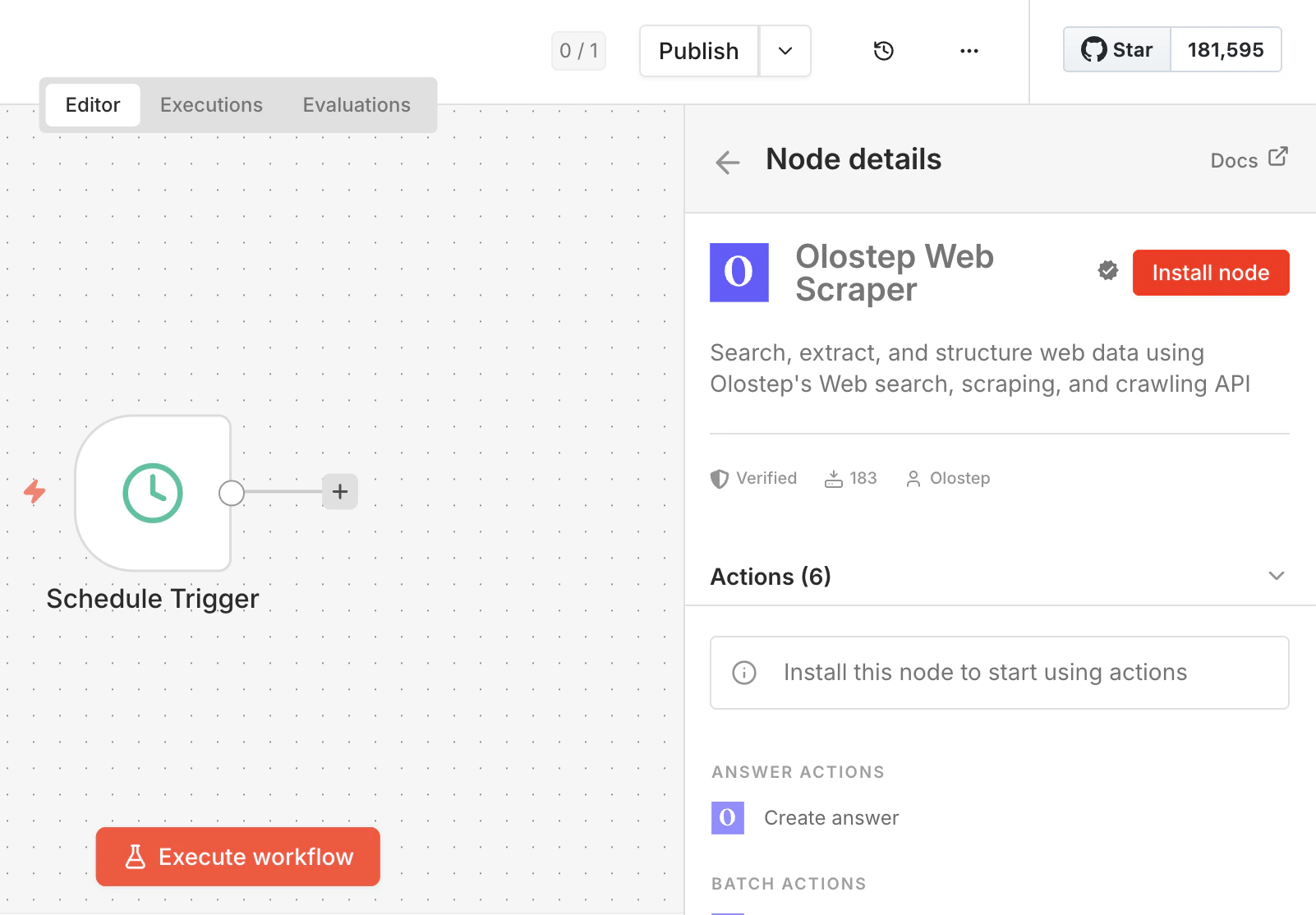
n8n-nodes-olostep installieren und dich auffordern, neu zu starten. Mach das, bevor du fortfährst.Wenn Community Nodes für deinen Arbeitsbereich deaktiviert ist, muss ein Administrator sie zuerst aktivieren. Siehe den n8n Community Nodes Leitfaden.
3
Füge deinen API-Schlüssel hinzu
Öffne den Olostep-Node in deinem Workflow, klicke auf Credential einrichten (im Parameter-Tab), füge deinen API-Schlüssel hinzu und klicke auf Speichern.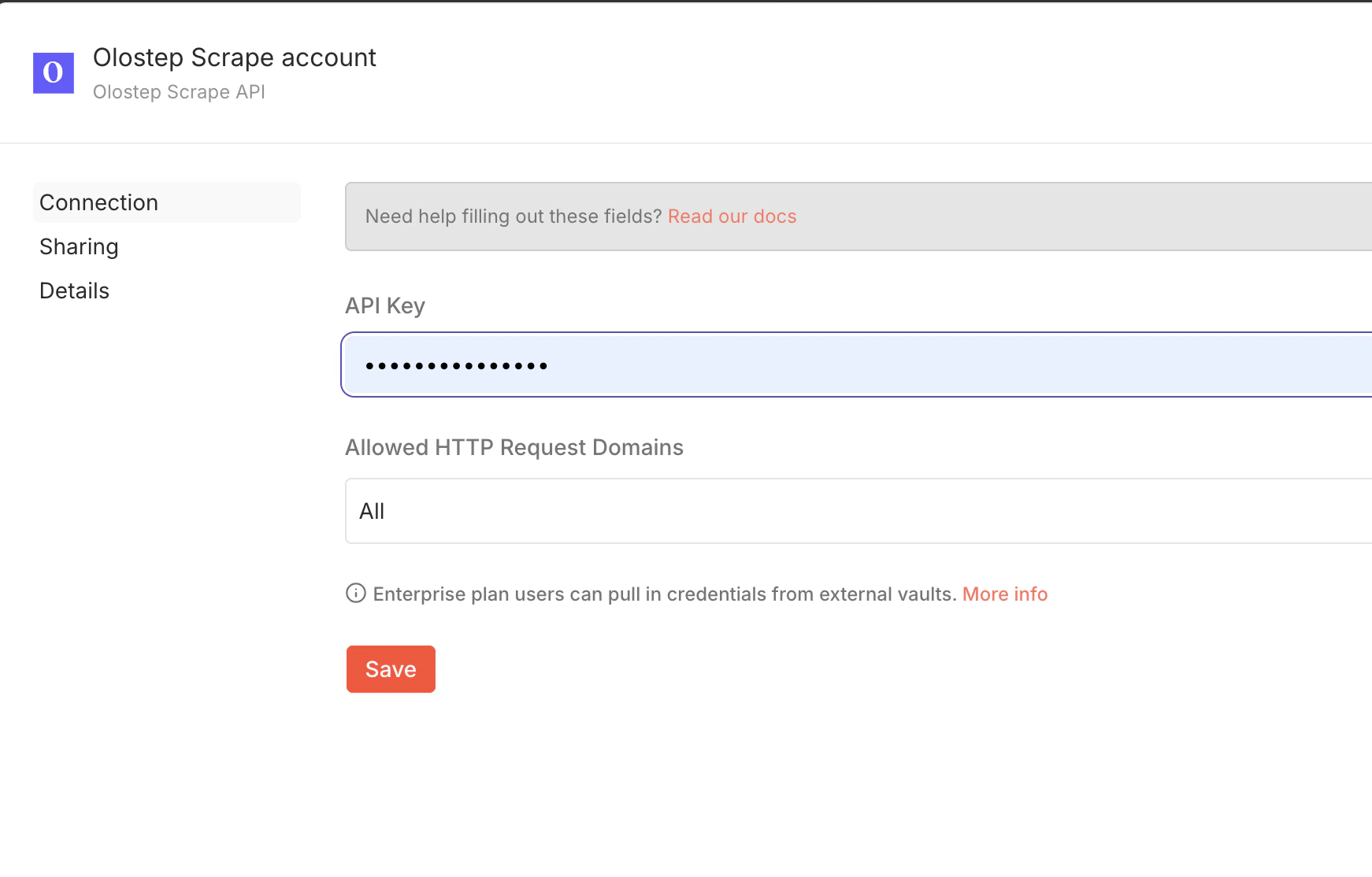
4
Verbinde und starte
Verbinde den Olostep-Node mit einem Trigger und allen nachgelagerten Schritten, dann führe deinen Workflow aus.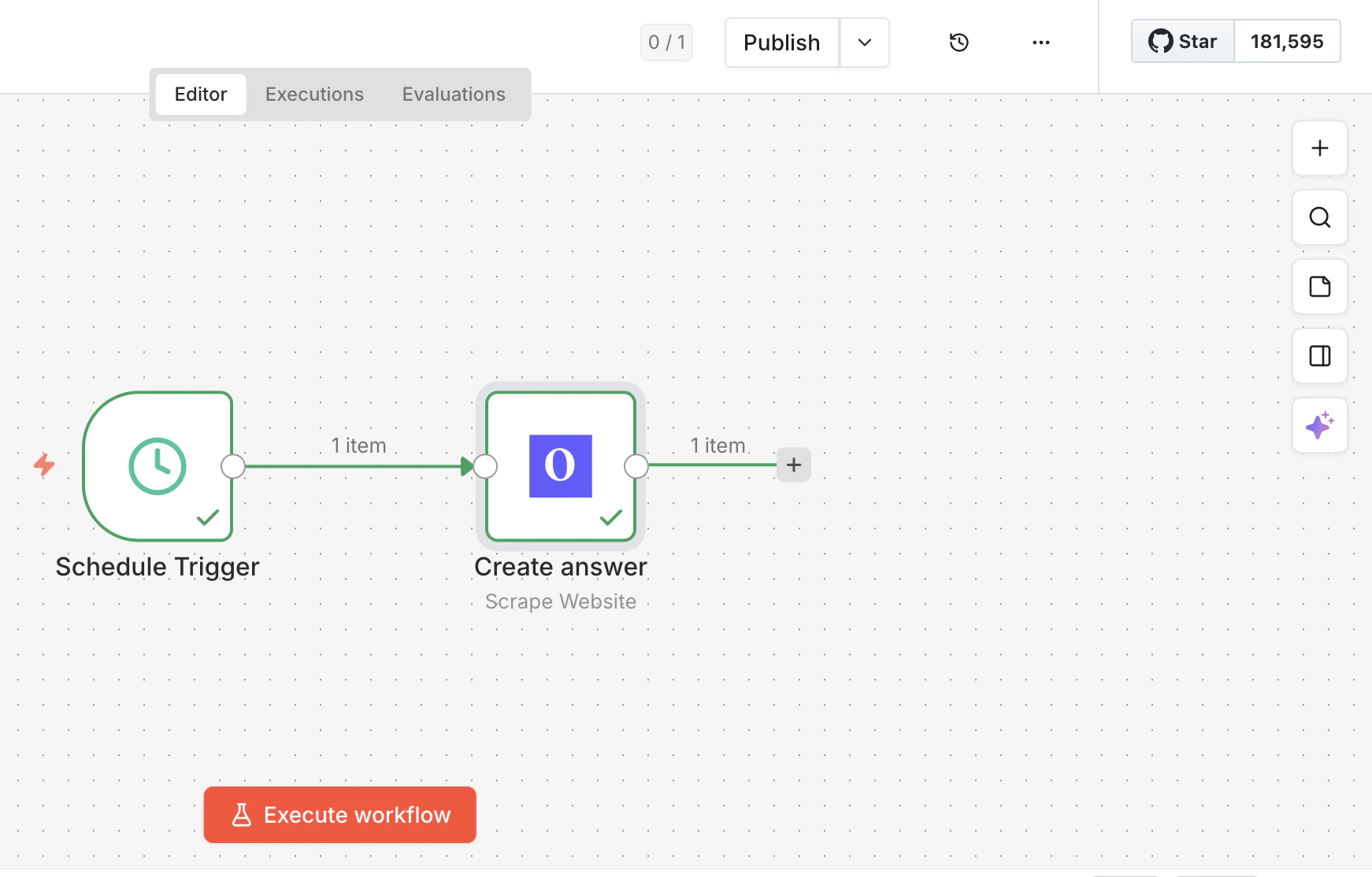
Aktionen
Website scrapen
Ziehe Inhalte von jeder URL als Markdown, HTML, JSON oder Klartext. Behandelt JS-gerenderte Seiten mit optionalen Wartezeiten und Länderausrichtung.
Suche
Führe eine Websuche durch und erhalte strukturierte Ergebnisse (Titel, URLs und Snippets) als JSON.
Antworten (KI)
Stelle eine Frage in natürlicher Sprache und erhalte eine Antwort mit zitierten Quellen. Nützlich vor LLM-Nodes, wenn du fundierte Antworten benötigst.
Batch-Scrape-URLs
Reiche bis zu 10.000 URLs in einem Job ein, die parallel verarbeitet werden. Gibt eine
batch_id zurück; Ergebnisse asynchron abrufen.Crawl erstellen
Beginne bei einer URL, folge Links und scrape alle Unterseiten. Gut für Dokumentationsseiten, Blogs oder vollständige Seitenaufnahme. Gibt eine
crawl_id zurück.Karte erstellen
Erhalte jede URL auf einer Seite, ohne Inhalte zu scrapen. Verwende es zur Entdeckung vor einem Batch-Job. Gibt eine
map_id zurück.Batch, Crawl und Map sind asynchron. Speichere die zurückgegebene ID und verwende einen Wait-Node oder einen zweiten Workflow, um Ergebnisse abzurufen, sobald die Verarbeitung abgeschlossen ist.
Beispiel-Workflow: Lead-Anreicherung aus Google Sheets
Was es tut: Wenn du eine Unternehmens-URL in ein Google Sheet einfügst, scrapt dieser Workflow automatisch die Website des Unternehmens, extrahiert wichtige Informationen mit einem KI-Node und schreibt die Ergebnisse in dieselbe Zeile zurück, wodurch ein leeres Tabellenblatt in eine ausgefüllte Lead-Datenbank verwandelt wird. Verwendete Nodes: Google Sheets Trigger → Olostep Scrape Website → OpenAI → Code → Google Sheets Update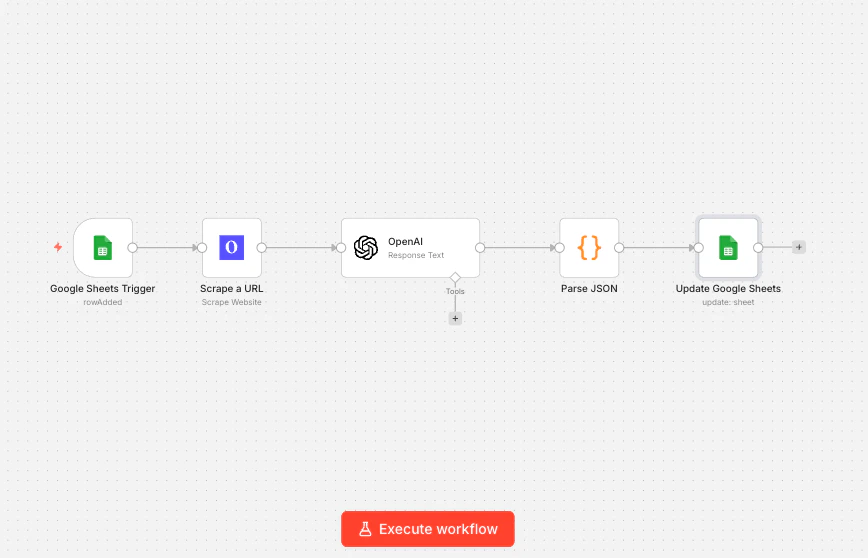
Schritt 1: Richte dein Google Sheet ein
Erstelle ein Blatt mit diesen Spalten:Company URL, Industry, Description, Company Size, Enriched. Der Workflow liest aus Company URL und füllt den Rest aus.
Schritt 2: Füge einen Google Sheets Trigger hinzu
Füge in n8n einen Google Sheets Trigger-Node hinzu. Setze das Ereignis auf Row Added, weise es deinem Blatt zu und setze es, um die SpalteCompany URL zu überwachen. Jedes Mal, wenn du eine neue URL in das Blatt einfügst, wird dieser Workflow ausgelöst.
Schritt 3: Füge Olostep Scrape Website hinzu
Verbinde einen Olostep Web Scraper Node nach dem Trigger. Setze:- Aktion: Website scrapen
- URL:
{{ $json["Company URL"] }}(zieht die URL aus der neuen Zeile) - Ausgabeformat: Markdown
Schritt 4: Füge einen OpenAI-Node hinzu
Verbinde einen OpenAI Node. Setze das Modell aufgpt-4o-mini (schnell und günstig für Extraktionsaufgaben) und verwende diesen Prompt:
markdownContent ist das, was Olostep aus dem Scrape zurückgibt, als sauberer Klartext.
Schritt 5: Analysiere die KI-Antwort und schreibe zurück
Füge einen Code Node hinzu, um das JSON von OpenAI zu analysieren:Industry→{{ $json.industry }}Description→{{ $json.description }}Company Size→{{ $json.company_size }}Enriched→Yes
Was du bekommst
Füge eine URL wiehttps://notion.so in dein Blatt ein, und innerhalb von ~10 Sekunden wird die Zeile ausgefüllt:
Von hier aus kannst du diesen Workflow erweitern: Füge eine Slack-Benachrichtigung hinzu, wenn die Anreicherung abgeschlossen ist, filtere nach Branche, bevor du zurückschreibst, oder ersetze Google Sheets durch HubSpot, um Kontakte direkt zu aktualisieren.
Vorlagen
Fertig importierbare n8n-Workflows, die mit Olostep erstellt wurden:Crawl-Dokumente → KI-Wissensdatenbank
Crawle Dokumentationsseiten mit Olostep und strukturiere die Ausgabe in eine KI-bereite Wissensdatenbank.
Google Maps Leads → Entscheidungsträger-Anreicherung
Scrape Geschäftskontakte von Google Maps und bereichere sie mit Entscheidungsträger-Details.
Nutzerbeschwerden analysieren → Erkenntnisbericht
Analysiere Beschwerden mit Olostep + Gemini und erstelle strukturierte Erkenntnisberichte in Google Docs.
Amazon-Produkt-Extraktion → Google Sheets
Extrahiere Amazon-Produkt-URLs und Metadaten mit Olostep und synchronisiere die Ergebnisse mit Sheets.
Parser
Füge eine Parser-ID in das Parser-Feld bei jeder Scrape- oder Batch-Aktion ein, um strukturierte Daten anstelle von rohen Inhalten zu erhalten:
Siehe die vollständige Liste im Olostep Parser Store →
Fehlerbehebung
API-Schlüssel abgelehnt
API-Schlüssel abgelehnt
Kopiere den Schlüssel direkt von olostep.com/dashboard ohne nachfolgende Leerzeichen. Lösche und erstelle die Anmeldeinformationen in n8n neu, wenn der Fehler weiterhin besteht.
Gescrapte Inhalte sind leer
Gescrapte Inhalte sind leer
Erhöhe Wartezeit vor dem Scrapen (versuche 2000–5000ms für JS-intensive Seiten). Bestätige, dass die URL öffentlich zugänglich ist, ohne dass ein Login erforderlich ist. Wenn eine bestimmte Domain konstant fehlschlägt, kontaktiere info@olostep.com.
Batch-URL-Formatfehler
Batch-URL-Formatfehler
Das Feld URLs zum Scrapen erwartet ein JSON-Array:Verwende einen Code-Node upstream, um dieses Array aus deinen Daten zu erstellen, falls erforderlich.
Rate-Limit erreicht
Rate-Limit erreicht
Füge einen Wait Node zwischen den Scrape-Schritten hinzu oder wechsle zu Batch-Scrape-URLs anstelle von einzelnen Scrapes in Schleifen. Überprüfe die aktuelle Nutzung im Dashboard.
Community Nodes nicht sichtbar in den Einstellungen
Community Nodes nicht sichtbar in den Einstellungen
Auf n8n Cloud müssen Community Nodes von einem Arbeitsbereichsbesitzer aktiviert werden. Bei selbstgehosteten Instanzen stelle sicher, dass
N8N_COMMUNITY_PACKAGES_ENABLED=true in deiner Umgebung gesetzt ist. Siehe n8n’s Installationsanleitung.Verwandte Themen
Scrapes API
Vollständige Referenz für den Scrape-Endpunkt
Batches API
Wie Batch-Jobs funktionieren und wie man Ergebnisse abruft
Crawls API
Crawl-Konfiguration und Ergebnisabruf
Maps API
URL-Entdeckung und Filteroptionen
Loslegen
Bereit, deine Websuche-, Scraping- und Crawling-Workflows zu automatisieren?n8n Website
n8n Plattform
Installiere den Node
Installiere n8n-nodes-olostep und beginne mit dem Aufbau automatisierter Workflows