始める前に
- APIキー付きのOlostepアカウント: 無料で取得、クレジットカードは不要です。最初の500クレジットが含まれています。
- n8nが稼働中: n8n Cloudまたはセルフホストのインスタンス。コミュニティノードが有効である必要があります(ほとんどのセットアップでデフォルトで有効です)。
- コーディング不要: このガイドのすべてはn8nのビジュアルエディタを通じて行われます。
セットアップ
1
Olostepノードを検索
任意のワークフローを開き、+をクリックしてOlostepを検索します。結果からOlostep Web Scraperを選択します。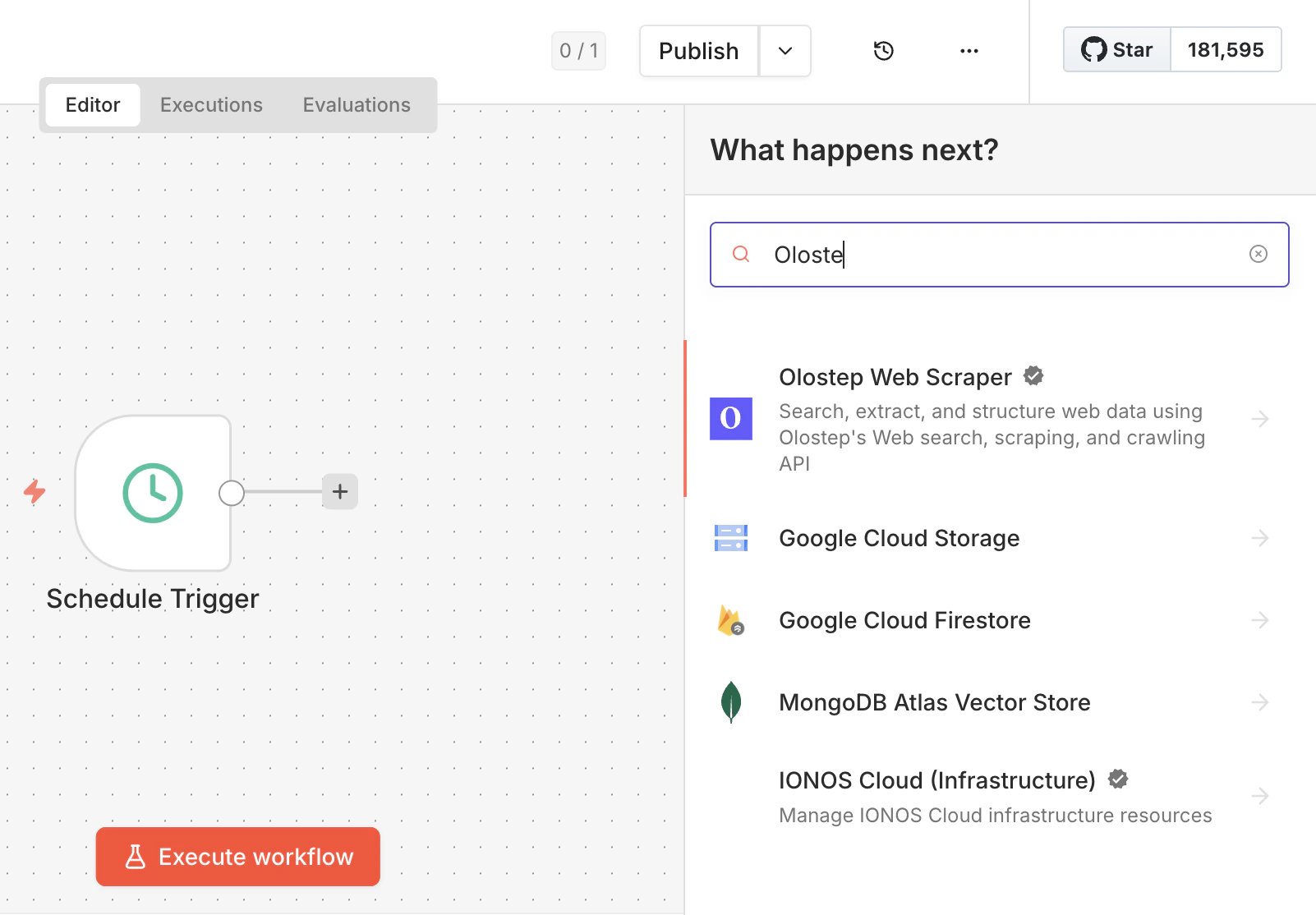
2
ノードをインストール
結果をクリックしてノード詳細パネルを開き、ノードをインストールをクリックします。n8nは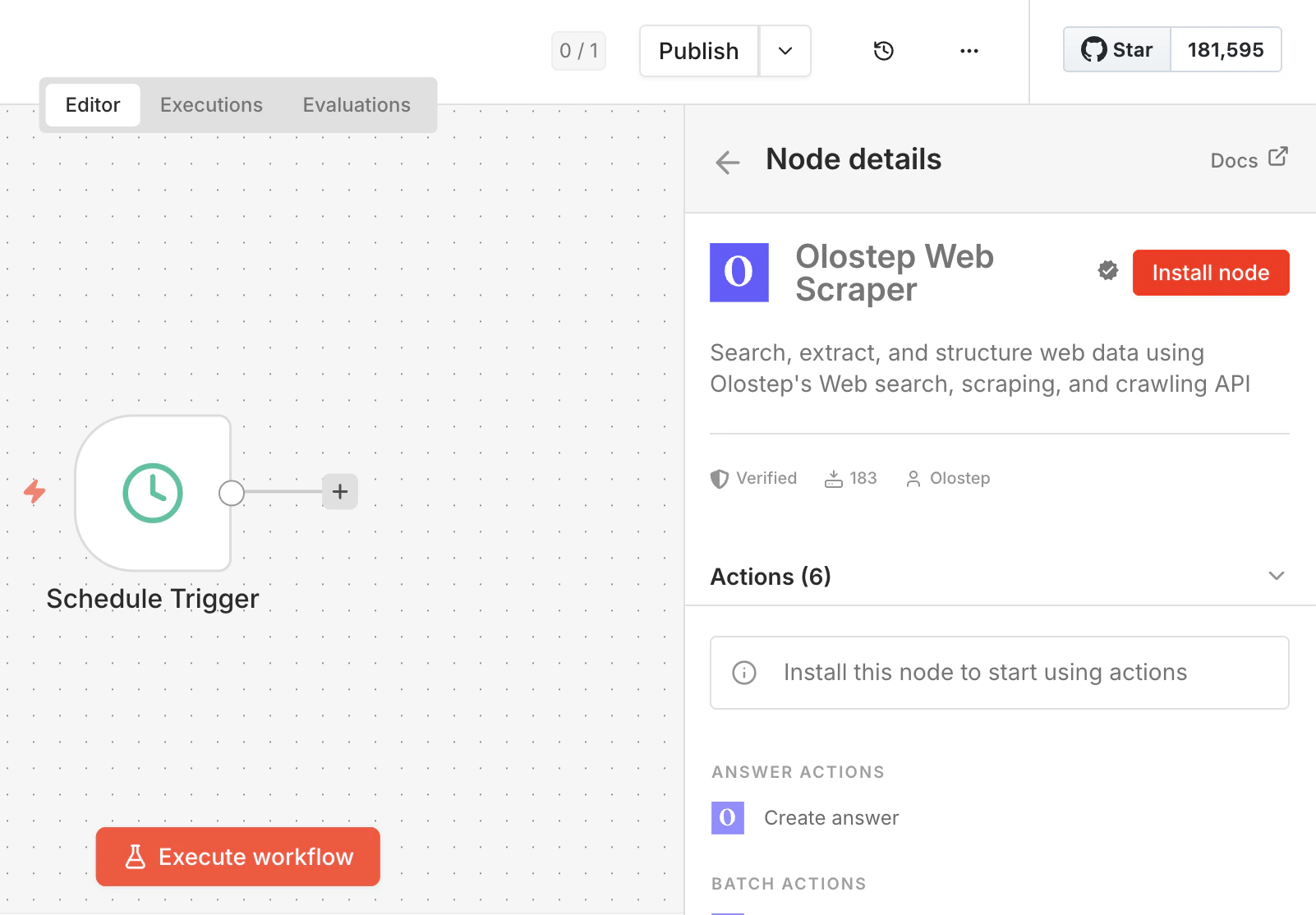
n8n-nodes-olostepをインストールし、再起動を促します。続行する前にそれを行ってください。ワークスペースでコミュニティノードが無効になっている場合、管理者が最初に有効にする必要があります。n8nコミュニティノードガイドを参照してください。
3
APIキーを追加
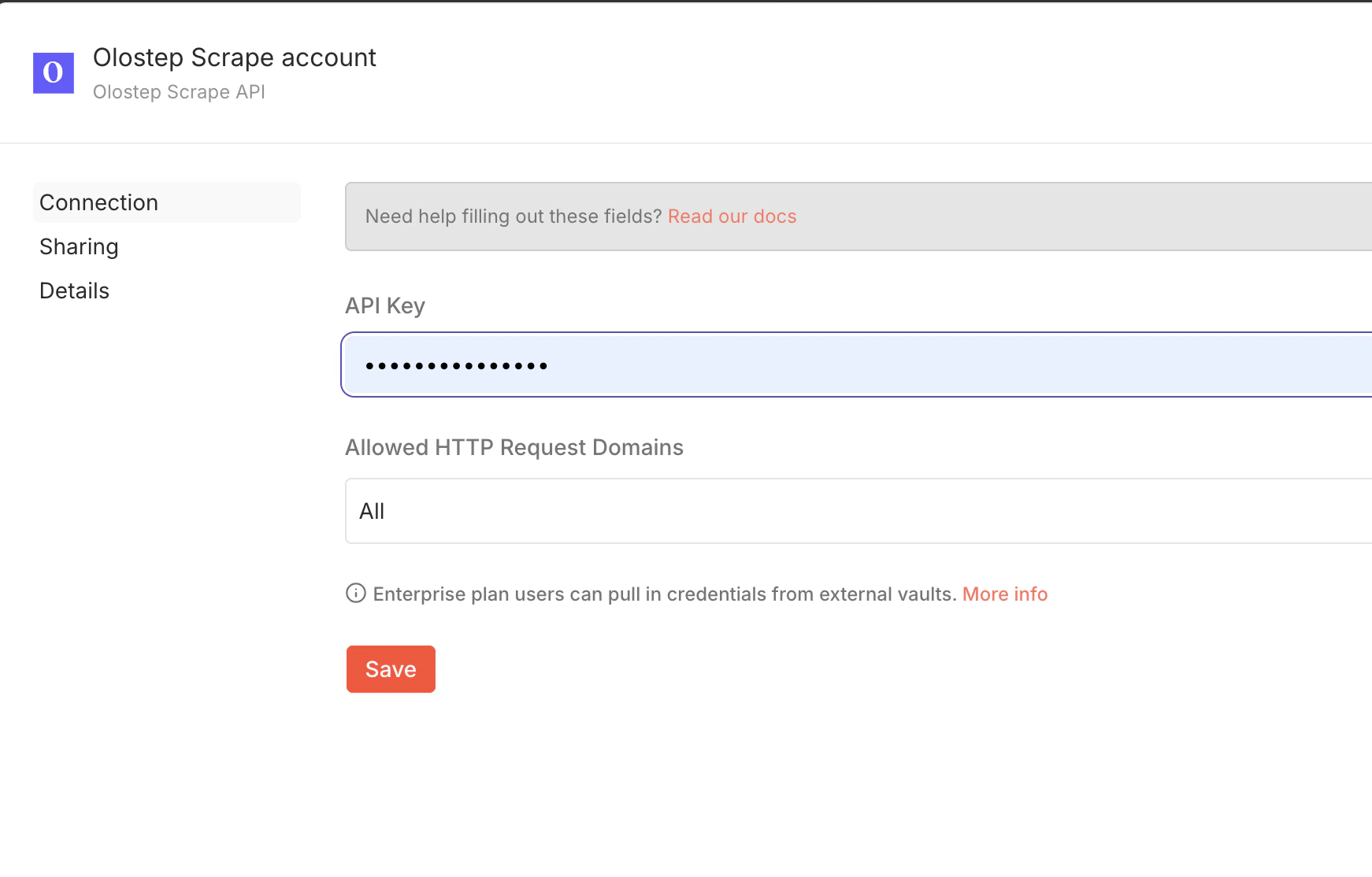
4
接続して実行
Olostepノードをトリガーと下流のステップに接続し、ワークフローを実行します。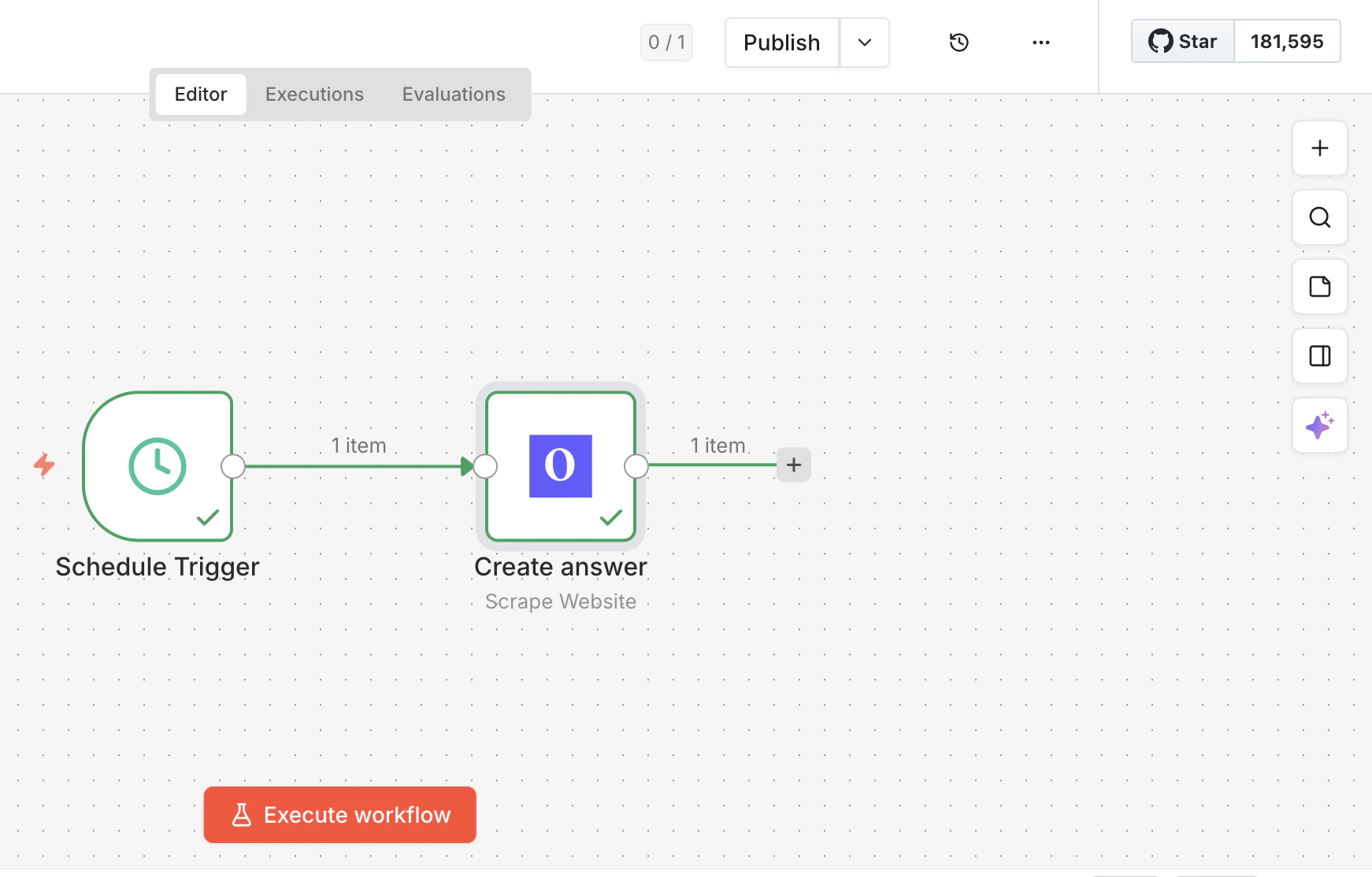
アクション
ウェブサイトをスクレイプ
任意のURLからコンテンツをMarkdown、HTML、JSON、またはプレーンテキストとして取得します。JSレンダリングされたページをオプションの待機時間と国ターゲティングで処理します。
検索
ウェブ検索を実行し、構造化された結果(タイトル、URL、スニペット)をJSONとして取得します。
回答(AI)
自然言語の質問をして、引用元付きの回答を取得します。LLMノードの前に、根拠のある回答が必要な場合に便利です。
URLをバッチスクレイプ
一度に最大10,000のURLを送信し、並行して処理します。
batch_idを返し、結果を非同期で取得します。クロールを作成
URLから始めてリンクをたどり、すべてのサブページをスクレイプします。ドキュメントサイト、ブログ、またはサイト全体の取り込みに適しています。
crawl_idを返します。マップを作成
コンテンツをスクレイプせずにサイト上のすべてのURLを取得します。バッチジョブの前に発見に使用します。
map_idを返します。バッチ、クロール、マップは非同期です。 返されたIDを保存し、処理が完了したら結果を取得するためにWaitノードまたは2番目のワークフローを使用します。
例のワークフロー: Google Sheetsからのリード強化
機能: Googleシートに会社のURLを貼り付けると、このワークフローは自動的に会社のウェブサイトをスクレイプし、AIノードで主要情報を抽出し、結果を同じ行に書き戻し、空白のスプレッドシートを充実したリードデータベースに変えます。 使用ノード: Google Sheetsトリガー → Olostep Scrape Website → OpenAI → Code → Google Sheets更新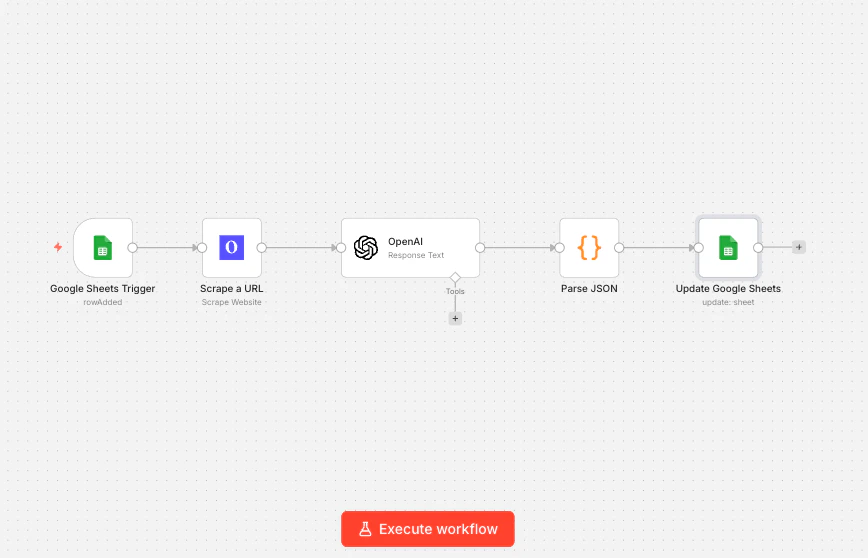
ステップ1: Google Sheetを設定
次の列を持つシートを作成します:Company URL, Industry, Description, Company Size, Enriched。ワークフローはCompany URLから読み取り、残りを埋めます。
ステップ2: Google Sheetsトリガーを追加
n8nで、Google Sheetsトリガーノードを追加します。イベントをRow Addedに設定し、シートを指し、Company URL列を監視するように設定します。これで、新しいURLをシートに貼り付けるたびに、このワークフローが発火します。
ステップ3: Olostep Scrape Websiteを追加
トリガーの後にOlostep Web Scraperノードを接続します。設定:- アクション: ウェブサイトをスクレイプ
- URL:
{{ $json["Company URL"] }}(新しい行からURLを取得) - 出力形式: Markdown
ステップ4: OpenAIノードを追加
OpenAIノードを接続します。モデルをgpt-4o-miniに設定し(抽出タスクに高速で安価)、次のプロンプトを使用します:
markdownContentフィールドは、Olostepがスクレイプから返すクリーンなプレーンテキストです。
ステップ5: AIの応答を解析して書き戻す
Codeノードを追加して、OpenAIからのJSONを解析します:Industry→{{ $json.industry }}Description→{{ $json.description }}Company Size→{{ $json.company_size }}Enriched→Yes
得られるもの
https://notion.soのようなURLをシートに貼り付けると、約10秒以内に行が埋まります:
ここからこのワークフローを拡張できます:強化が完了したらSlack通知を追加したり、書き戻す前に業界でフィルタリングしたり、Google SheetsをHubSpotに置き換えて直接連絡先を更新したりします。
テンプレート
Olostepで構築されたn8nワークフローをすぐにインポート:ドキュメントをクロール → AI知識ベース
Olostepでドキュメントサイトをクロールし、AI対応の知識ベースに構造化します。
Google Mapsリード → 意思決定者の強化
Google Mapsからビジネスリードをスクレイプし、意思決定者の詳細で強化します。
ユーザーの苦情をマイニング → インサイトレポート
Olostep + Geminiで苦情を分析し、Google Docsで構造化されたインサイトレポートを生成します。
Amazon製品の抽出 → Google Sheets
OlostepでAmazon製品のURLとメタデータを抽出し、結果をSheetsに同期します。
パーサー
任意のスクレイプまたはバッチアクションでParserフィールドにパーサーIDを追加して、未加工のコンテンツの代わりに構造化データを取得:
Olostepパーサーストアで完全なリストを見る →
トラブルシューティング
APIキーが拒否される
APIキーが拒否される
olostep.com/dashboardからキーを直接コピーし、末尾にスペースがないことを確認してください。エラーが続く場合は、n8nで資格情報を削除して再作成してください。
スクレイプされたコンテンツが空
スクレイプされたコンテンツが空
スクレイプ前の待機を増やします(JSが多いページには2000〜5000msを試してください)。URLがログインなしで公開アクセス可能であることを確認してください。特定のドメインが一貫して失敗する場合は、info@olostep.comに連絡してください。
バッチURL形式エラー
バッチURL形式エラー
スクレイプするURLフィールドはJSON配列を期待しています:必要に応じて、データからこの配列を作成するために上流にCodeノードを使用します。
レート制限に達した
レート制限に達した
スクレイプステップ間にWaitノードを追加するか、単一スクレイプをループする代わりにBatch Scrape URLsに切り替えます。ダッシュボードで現在の使用状況を確認してください。
設定でコミュニティノードが見えない
設定でコミュニティノードが見えない
n8n Cloudでは、コミュニティノードはワークスペースオーナーが有効にする必要があります。セルフホストでは、
N8N_COMMUNITY_PACKAGES_ENABLED=trueが環境に設定されていることを確認してください。n8nのインストールガイドを参照してください。関連
Scrapes API
スクレイプエンドポイントの完全なリファレンス
Batches API
バッチジョブの動作と結果の取得方法
Crawls API
クロールの設定と結果の取得
Maps API
URLの発見とフィルタリングオプション
始めよう
ウェブ検索、スクレイピング、クロールワークフローを自動化する準備はできましたか?n8nウェブサイト
n8nプラットフォーム
ノードをインストール
n8n-nodes-olostepをインストールして自動化ワークフローを構築し始めましょう