始める前に
- APIキー付きのOlostepアカウント: 無料で取得、クレジットカードは不要です。最初の500クレジットが含まれています。
- Zapierアカウント: どのプランでも動作します。無料プランは手動でZapを実行できます。有料プランはスケジュールされたZapやマルチステップZapをサポートします。
- コード不要: このガイドのすべてはZapierのビジュアルエディタを通じて行われます。
セットアップ
1
ZapierでOlostepを見つける
任意のZapを開き、アクションを追加するために**+をクリックし、Olostepを検索します。結果からOlostep**を選択します。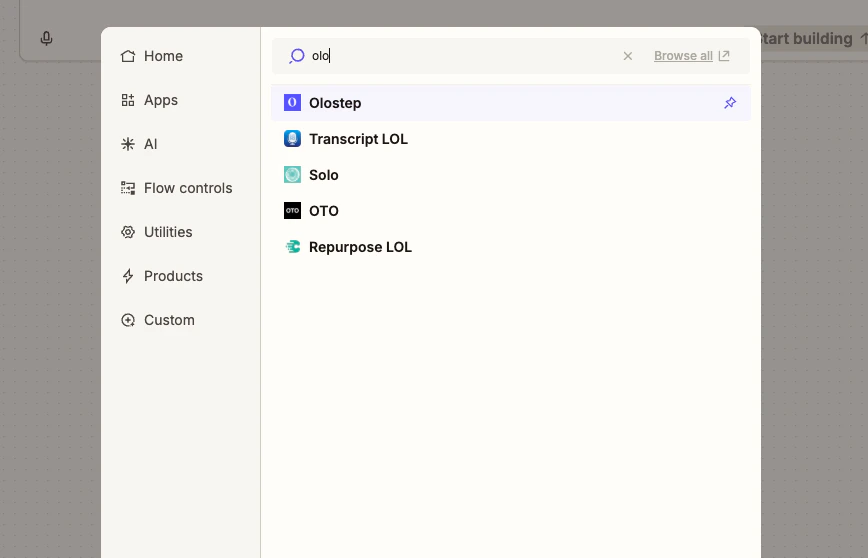
2
アカウントを接続する
Olostepにサインインをクリックします。APIキーをフィールドに貼り付け、はい、Olostepに続行をクリックします。Zapierはキーを確認し、今後のすべてのZapのために資格情報を保存します。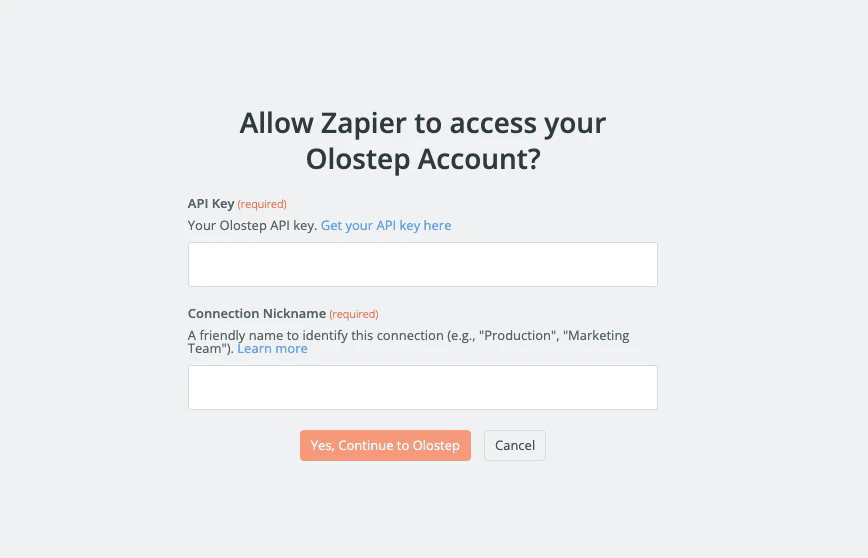
3
アクションを選択する
アカウントが接続されたら、アクションドロップダウンから5つのOlostepアクションの1つを選び、必要なフィールドを入力します。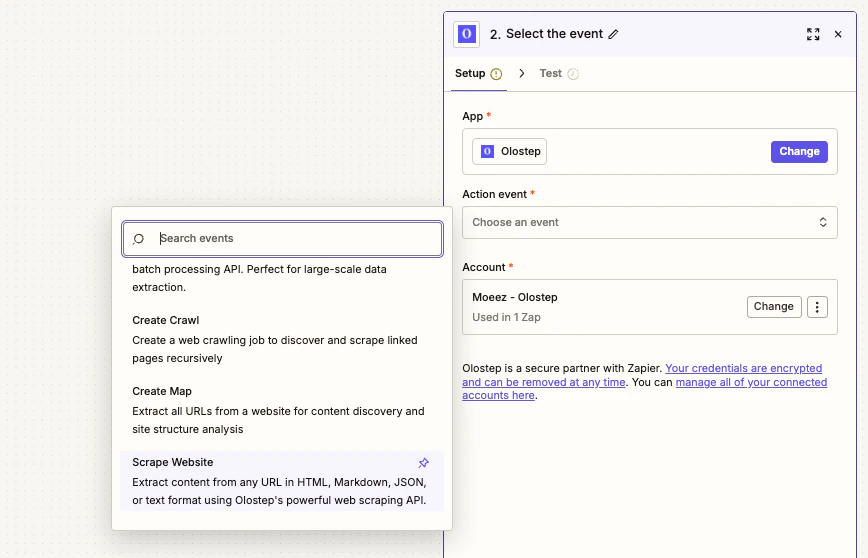
4
ウェブサイトをスクレイピングする(URL + フォーマットを設定)
- スクレイピングするURL: トリガーからマップするか手動で入力します
-
出力フォーマット:
Markdown、HTML、JSON、またはTextを選択します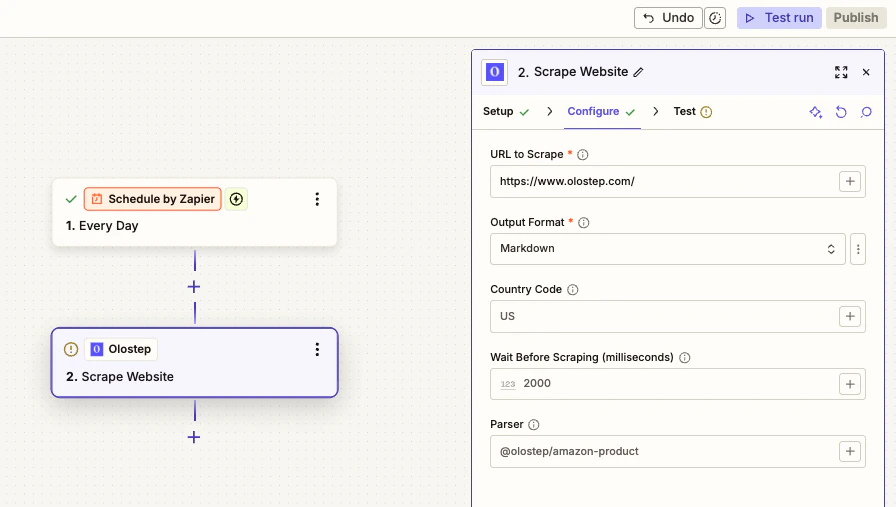
5
テストと公開
テストステップをクリックしてライブリクエストを実行し、出力を確認します。正しければ、下流のステップを接続し、Zapを公開します。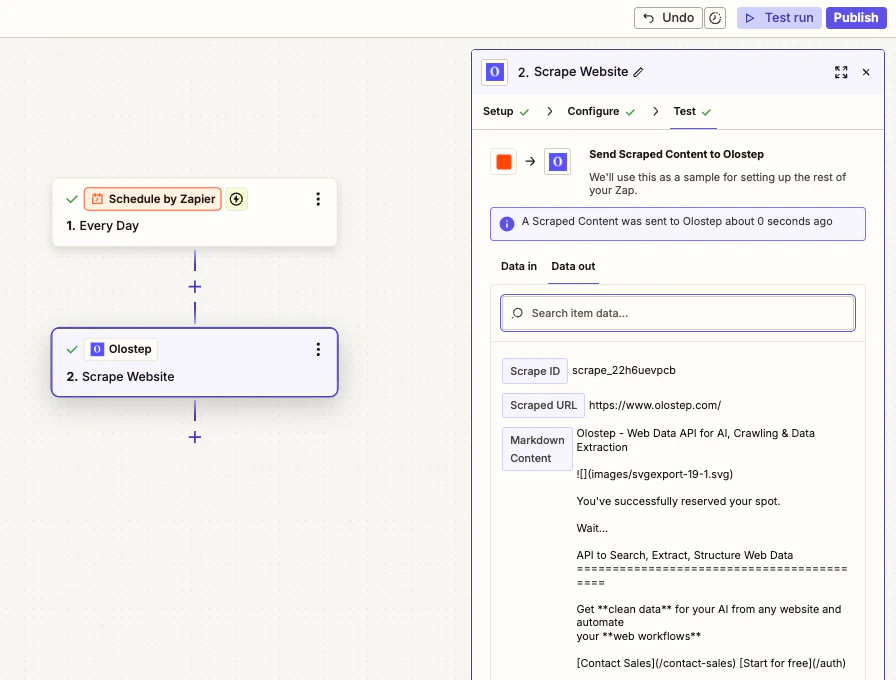
アクション
ウェブサイトをスクレイピング
任意のURLからMarkdown、HTML、JSON、またはプレーンテキストとしてコンテンツを取得します。JSレンダリングされたページをオプションの待機時間と国のターゲティングで処理します。
AI回答を尋ねる
自然言語の質問をして、提供されたページやライブウェブ検索に基づいた引用付きの回答を得ます。
URLをバッチスクレイピング
1つのジョブで最大100,000のURLを提出し、並行して処理します。
batch_idを返し、結果を非同期で取得します。クローリングを作成
URLから開始し、リンクをたどり、すべてのサブページをスクレイピングします。ドキュメントサイト、ブログ、またはフルサイトの取り込みに適しています。
crawl_idを返します。マップを作成
コンテンツをスクレイピングせずにサイト上のすべてのURLを取得します。バッチジョブの前に発見に使用します。
map_idを返します。バッチ、クローリング、マップは非同期です。 返されたIDを保存し、処理が完了したら結果を取得するためにDelayステップまたは2つ目のZapを使用します。
例のワークフロー: 毎日の競合他社ブリーフィング
内容: 毎朝、このZapは競合他社のページをスクレイピングし、Olostep AI Answerにそのページからの主要な更新を要約させ、最終的なブリーフィングを引用付きでSlackに投稿します。 使用ノード: Schedule by Zapier -> Olostep Scrape Website -> Olostep Ask AI Answer -> Slack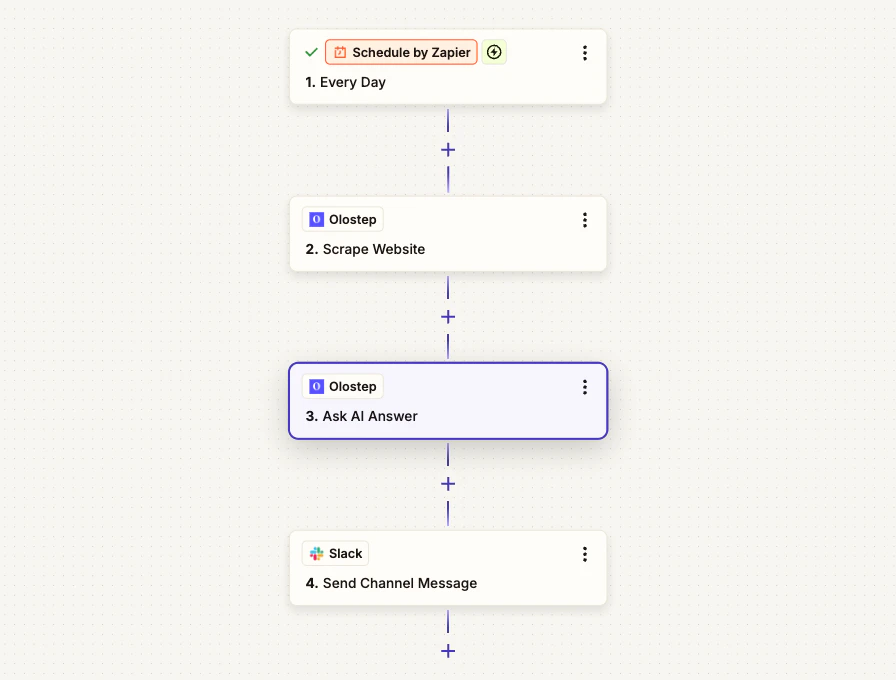
ステップ 1: スケジュールトリガーを追加
Zapierで新しいZapを作成し、トリガーをSchedule by Zapierに設定します。チームに適した時間(例: 午前8時)に毎日実行するように設定します。ステップ 2: Olostep Scrape Websiteを追加
Olostepアクションを追加し、Scrape Websiteを選択します。設定:- URL:
https://competitor.com/blog - 出力フォーマット: Markdown
ステップ 3: Olostep Ask AI Answerを追加
2つ目のOlostepアクションを追加し、Ask AI Answerを選択します。設定:- 質問:
今日このページでの主要な更新、発表、製品変更、または価格変更は何ですか?箇条書きで簡潔なブリーフィングを返し、引用を含めてください。 - コンテキストURL(JSON配列): ステップ2からのスクレイピングされたURLをマップ
- フォーマット: Markdown
- 引用を含める: true
ステップ 4: Slackに送信
Slackアクションを追加し、チャンネルメッセージを送信に設定します。マップ:- チャンネル:
#competitive-intel - メッセージテキスト:
Daily Competitor Briefing - メッセージ本文:
{{Answer (Markdown)}}
得られるもの
毎朝、Slackチャンネルに次のようなメッセージが届きます:Daily Competitor BriefingここからこのZapを拡張できます: 特定のキーワードが出現した場合のみ投稿するようにフィルターを追加したり、追跡のためにGoogle Sheetsにブリーフィングを書き込んだり、異なる競合他社のURL用に別のZapを実行したりします。Sources: competitor.com/blog, competitor.com/pricing
- 新しいeコマースワークフロー用の統合を開始
- 新しい中間層プランで価格ページを更新
- 自動化のベストプラクティスに関する2つの新しいブログ投稿を公開
パーサー
任意のスクレイプまたはバッチアクションのParserフィールドにパーサーIDを追加して、生のコンテンツではなく構造化データを取得します:
Olostepパーサーストアで完全なリストを見る →
Zapierの制限と回避策
タスク制限
Zapierは各アクションをプランの制限に対する1つのタスクとしてカウントします。 回避策: Batch Scrape URLsを使用して、単一のスクレイプアクションをループする代わりに複数のURLを単一のタスクとして処理します。実行タイムアウト
Zapは30秒後にタイムアウトします。クローリングや大規模なバッチジョブはそれ以上の時間がかかります。 回避策: 返されたcrawl_idまたはbatch_idを保存し、Webhookやスケジュールされた遅延でトリガーされた別のZapで結果を取得します。
データサイズ制限
Zapierはステップ間で渡せるデータサイズを制限しており、大きなスクレイプペイロードで問題になることがあります。 回避策: Olostepが返すホストされた出力URLを使用して、大きなコンテンツを別途取得し、生のコンテンツをステップ間で渡すのではなくします。ポーリングトリガー
ほとんどのZapierトリガーは5〜15分間隔でポーリングし、即時ではありません。 回避策: ZapierのWebhooksトリガーを使用して即時通知を受け取るか、リアルタイムに近いポーリングに頼るのではなく、固定時間にZapをスケジュールします。トラブルシューティング
APIキーが拒否される
APIキーが拒否される
olostep.com/dashboardからキーを直接コピーし、末尾のスペースがないことを確認します。エラーが続く場合は、ZapierでOlostepアカウントを切断して再接続します。
スクレイピングされたコンテンツが空
スクレイピングされたコンテンツが空
スクレイピング前の待機時間を増やします(JSが多いページには2000〜5000msを試してください)。URLがログインなしで公開アクセス可能であることを確認します。特定のドメインが一貫して失敗する場合は、info@olostep.comに連絡してください。
バッチURLフォーマットエラー
バッチURLフォーマットエラー
スクレイプするURLフィールドはJSON配列を期待しています:必要に応じて、データからこの配列を構築するために上流でCode by Zapierステップを使用します。
レート制限に達した
レート制限に達した
スクレイプアクション間にDelayステップを追加するか、単一のスクレイプをループする代わりにBatch Scrape URLsに切り替えます。現在の使用状況はダッシュボードで確認できます。
クローリングやバッチでZapがタイムアウトする
クローリングやバッチでZapがタイムアウトする
これらの操作は設計上非同期です。アクション直後に返されたIDを保存し、後で結果を取得するために2つ目のZapまたはスケジュールされたポーリングを使用します。
関連
スクレイプAPI
スクレイプエンドポイントの完全なリファレンス
バッチAPI
バッチジョブの仕組みと結果の取得方法
クローリングAPI
クローリングの設定と結果の取得
マップAPI
URLの発見とフィルタリングオプション
Zapierウェブサイト
Zapierプラットフォーム